在最近的 IEEE 國際固態電路會議 ( ISSCC ) 上,三星科學家發表了一篇論文,繼續推動 DDR5 效能的進步。

三星的目標是透過其新提出的架構將 DRAM 容量提高一倍。
這篇題為 "在第五代 10 奈米 DRAM 工藝中采用對稱馬賽克架構(Symmetric-Mosaic)的 32-Gb 8.0-Gb/s/pin DDR5 SDRAM "的論文涵蓋了目前使用的 16-Gb 架構的局限性和三星提出的對稱馬賽克布局。在本文中,我們將總結論文中概述的架構的關鍵元件。
單片裸片(DIE):從 16-Gb 到 32-Gb
目前,最高容量的 DDR5 記憶體采用基於 16 Gb 裸片並采用 10 奈米工藝制造的三維堆疊 (3DS) 架構。目前主流的終端產品是64GB DDR5 DRAM模組,128GB模組的需求不斷增加。
三星論文描述了一款單片 32 Gb 高密度 DDR5 裸片,仍采用 10 奈米工藝。三星聲稱,基於 32 Gb 裸片的 3DS 系統將提高效能,在八個芯片堆疊中使用時支持高達 1TB 的記憶體,並實作每個引腳每秒 8 Gb 的速度。
業界認識到需要轉向 32 Gb 裸片。然而,存在許多障礙。小於 10 nm 的 DRAM 節點尚未準備就緒,因此芯片制造商必須找到在不改變晶圓廠工藝的情況下增加產能的方法。此外,當前 DRAM 模組的外形尺寸過於固定,無法在不顯著提高容量或效能的情況下增加封裝尺寸。
「馬賽克」架構分區克服傳統 DRAM 大小限制
32 Gb 裸片將是一種適應,而不是新標準,因此必須適應傳統的 JDEC 規定的 DDR5 外形尺寸限制(最大 10 公釐 x 11 公釐)。在不減小工藝尺寸的情況下增加容量的傳統方法包括在儲存體中添加 DRAM 單元或將邏輯儲存體中的物理儲存體數量加倍。這會導致矩形記憶體占用空間在垂直或水平方向上超過 10 mm x 11 mm 封裝尺寸邊界框。
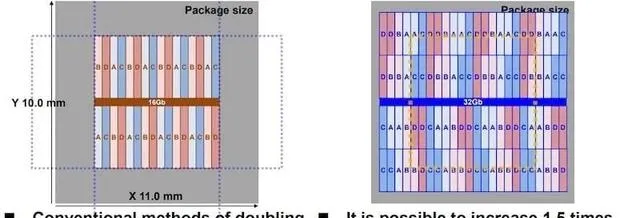
傳統方法(左)和對稱鑲嵌方法(右)裸片容量增加的比較。
在所提出的架構中,每個邏輯儲存體被分為 ⅓ 和 ⅔ 分區。它們作為邏輯儲存體不同分區的對稱鑲嵌體而間隔開。這使得 DRAM 容量增加了一倍,而水平面積和垂直面積僅增加了 1.5 倍和 1.33 倍(適合邊界框)。
來自不同邏輯儲存體的兩個分區將共享相同的全域 I/O (GIO) 訊號線和讀出放大器。這種共享減少了 GIO 路線負載電容,從而提高了速度並降低了功耗。這種物理布局將 I/O 保持在中心,與 16-Gb 芯片中使用的一樣,共享相同的焊盤結構,並利用類似的矽通孔 (TSV) 結構來連線 3DS 層。
對稱馬賽克架構
GIO 線的「馬賽克」交錯和共享利用了保證讀到讀和寫到寫時序規範 (tCCD_L) 的精確時序。物理儲存體作為邏輯儲存體進行劃分和存取,tCCD_L 特性用於指示時序。
提高速度並減少幹擾
要在如此高的速度下保持數據準確,需要額外的邏輯來實作所謂的決策反饋均衡 (DFE)。高速數位並不是低速情況下簡單的「開/關」電壓轉換。訊號是圓形的、受到幹擾的,並且通常表現得更像模擬而不是數位。訊號線電容和電阻實質上建立了具有 R/C 時間常數的濾波器,該濾波器會扭曲並阻礙攜帶資訊的訊號(符號)。一個符號的影響可能會滲透到下一個符號,或者來自接收元件的反射可能會使符號失真,從而導致符號間幹擾 (ISI),必須減輕這種幹擾以防止無效數據。
三星提出的架構在傳統 DFE 電路中添加了四抽頭系統,這是傳統兩抽頭 DFE 的替代方案。在 DFE 電路中,抽頭被反饋到輸入並求和。四抽頭直接反饋一抽頭以最大限度地減少反饋延遲。第二、第三和第四抽頭使用電流模型邏輯 (CML) 求和來進一步提高符號精度。
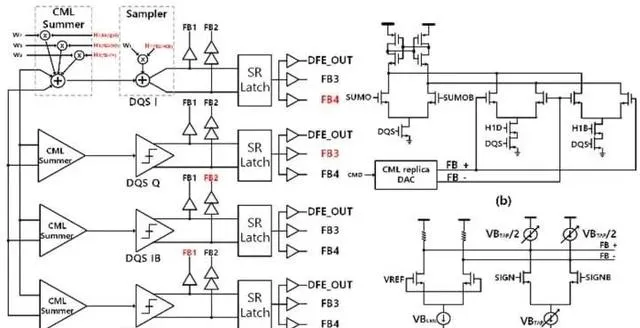
(a) 四抽頭 DFE。(b) 點選一個直接給采樣器供料。(c) 將二到四分接至 CML 電路。
DFE 與 DQ 緩衝區中的自動偏移電壓校準電路一起執行。校準電路透過使用四個路徑進行四個操作階段來補償偏移,並根據四個路徑輸出的直接多數表決進行校準。其結果是能夠以 8 Gb/s 或更快的速度可靠執行。
芯片ID預解碼
由於每個芯片的 RAM 單元加倍,功耗變得比 16 Gb 芯片更加重要。由於這些芯片將主要安裝在 3D 堆疊配置中,因此芯片制造商必須改進針對低效芯片的流程。
「rank」是物理儲存體的邏輯組合集,其承載與片上數據匯流排相同的數據字寬。它可以在物理芯片內形成,也可以在 3D 堆疊芯片系統中跨多個芯片形成。例如,八個堆疊管芯中每一個的左上象限可以組合成一個8位元邏輯列並作為一個8位元邏輯列進行尋址。
在標準配置中,命令帶有芯片 ID (CID) 進入命令匯流排。然後所有等級都執行解碼以檢視它們是否是預期目標。解碼完成後,僅遵循預期的排名。讓所有級別執行解碼操作會浪費大量的功率。
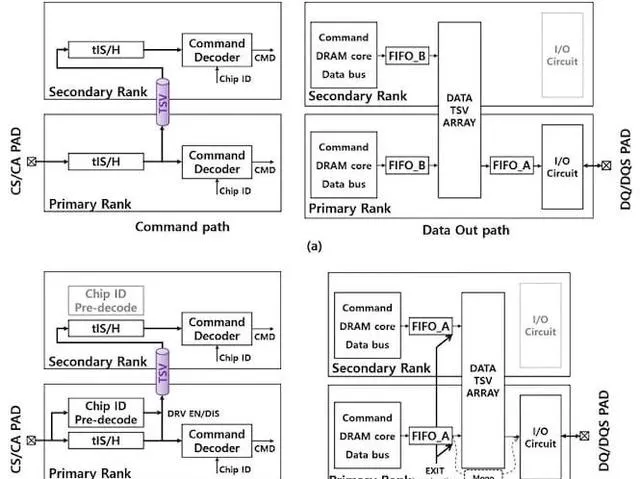
(a) 傳統的 CID 解碼堆疊和 (b) 三星提出的預解碼系統。
該提議的架構在每個等級中都帶有芯片 ID 預解碼。借助此類功能,主列在 TSV 之前具有預解碼電路。如果 CID 不是預期目標,它只會將其發送到下一個等級。本質上,堆疊中的每個等級都會在 CID 成為預期目標時停止它。如果堆疊中的最後一個等級是預期目標,則不會節省電量,但對於頂部以下的所有等級,則會節省一定比例的電量。
在當今的外形尺寸內取得進步
三星提出的架構可以在不改變整體外形尺寸或減少芯片蝕刻幾何尺寸的情況下大幅提高 DRAM 容量。透過使用更高效的非傳統組織結構,可以在不改變標準或工廠的情況下,在相同的面積內容納更多的容量。建議的架構采用邏輯等級、時序特異性和資源共享來增加容量、降低功耗和提高最高速度。
根據三星的測算,基於 32 GB 的 0.5 TB DIMM 比基於 16 GB 的 DIMM 功耗低 30%,使其成為數據中心和其他容量和功耗要求較高的計算套用的理想選擇。











