6月15日,智源大會「多模態大模型」論壇中,紐約大學助理教授謝賽寧從哲學的角度出發,分享了 AI是否需要更強的視覺基礎來實作理解和意義 。
昨天,楊立坤、謝賽寧團隊推出其最新研究工作,聚焦多模態模型視覺,釋出以視覺為中心的多模態大語言模型(MLLM)-- Cambrian-1 。
3.5研究測試:
hujiaoai.cn
4研究測試:
askmanyai.cn
Claude-3研究測試:
hiclaude3.com
Cambrian-1不僅實作了SOTA,還提供了一個全面的、開放的指令調優MLLMs的指南,並且 完全開源 。

謝賽寧本科畢業於上海交通大學,曾在Facebook人工智慧研究院擔任研究科學家謝賽寧從Meta離職,加入紐約大學擔任助理教授。
論文題目:
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
論文連結:
https://arxiv.org/pdf/2406.16860
接下來,讓我們來看看研究的具體細節。
總的來說,Cambrian-1在傳統協定與使用MLLMs評估視覺表示之間建立了聯系,使用MLLM指令微調作為各種視覺表示的評估協定,MLLMs透過視覺問答來解決多種現實世界中的感知任務。

如上圖底部的架構所示,Cambrian-1的構建包括 五個關鍵支柱 :
我們將對"五大支柱"逐一展開簡要介紹,具體詳情請查閱論文。
視覺表示
在研究提出的基準測試上進行評估,計算每個類別的平均效能。
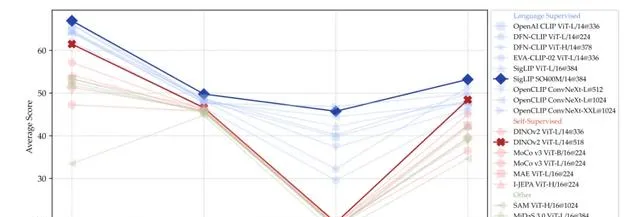
語言監督模型在所有基準測試類別上優於非CLIP模型,特別是在圖表和OCR相關基準測試中表現顯著優越。謝賽寧團隊推測,這可能是由於CLIP的訓練封包含大量OCR和文本內容豐富的數據,而自監督學習(SSL)和其他視覺模型主要訓練於自然影像,其中文本內容顯著較少。
高分辨率編碼器極大增強了圖表和視覺中心基準測試的效能,並且基於ConvNet的架構天生適合這些任務。
縮小語言監督模型與自監督模型之間的差距:
觀察到DINOv2在一般和知識基準測試中處於自監督模型和語言監督模型之間,甚至在更高分辨率的視覺中心基準測試上表現出色,超過了一些語言監督模型。
在這裏,我們研究繼續基於自監督模型進行微調的MLLM是否能夠達到與語言監督模型類似的效能水平。
考慮到DINOv2相比於CLIP使用的數據要少得多,我們探討增加視覺微調數據量並解凍視覺編碼器,以彌合這一差距。

我們觀察到,透過解凍視覺編碼器,基於DINOv2的MLLM在使用5M數據進行微調後超過了使用0.7M數據訓練的CLIP模型的MLLM。此外,在5M數據設定下,DINOv2和CLIP模型之間的差距也有所縮小。
語言監督提供了強大的優勢,但透過足夠的數據和適當的調整,可以縮小與自監督方法之間的效能差距。
探索結合多個視覺編碼器的潛力
不同的視覺編碼器在MLLM效能的不同方面表現出色。在這項研究中,我們探索結合多個視覺編碼器的潛力,利用它們獨特的表示來構建一個更強大的MLLM。
考慮到不同的視覺編碼器使用不同的架構和影像分辨率,我們對視覺令牌插值到固定數量(576個),並沿特征維度拼接這些令牌。
研究表明,添加一個非語言監督模型(如DINOv2)可以改善基準測試的效能,特別是在視覺中心任務中。值得註意的是,即使是OCR基準也受益於整合DINOv2。這突顯了自監督學習模型在補充語言監督模型以實作強大的多模態理解方面的重要性。
結合多個視覺編碼器,包括視覺自監督學習模型,在各種基準測試中提升了MLLM的效能,特別是在視覺中心任務中。
這種簡單的策略存在兩個限制:1)它使用插值,可能會導致資訊遺失,特別是對於具有高分辨率特征圖的視覺編碼器;2)它透過簡單拼接平等對待每個模型。因此,我們尋求一種更有效的策略,能夠更靈活地利用模型組合,減少資訊損失。
連結器設計
為了有效地聚合多個視覺編碼器的特征並防止插值引入的資訊損失,我們采用一組可學習的潛在查詢,透過交叉註意力層與多個視覺特征進行互動。特別是,我們的方法引入了兩個新的視覺中心設計原則:
- 我們透過明確定義每個查詢令牌的聚合空間,引入了空間歸納偏差。我們在LLM層之間多次聚合視覺特征,使模型能夠重復存取和整合必要的視覺資訊。
- 我們的新表述靈活地適應了具有不同特征分辨率的多個視覺編碼器,同時在聚合過程中保持了視覺數據的空間結構,並與LLM整合。
我們提出的SVA是一種動態和空間的感知連結器。它能將多種視覺特征與 LLM 整合在一起,同時減少標記的數量。
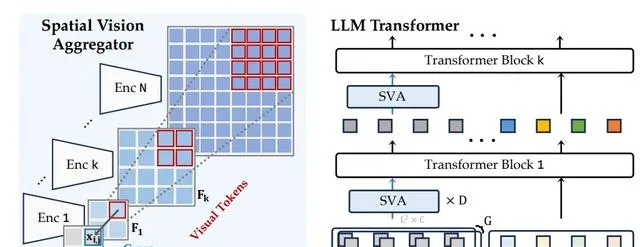
SVA在所有基準類別中均優於兩個基線方法,並在OCR和圖表類別(需要高分辨率特征理解)中表現出顯著改進。相比之下,缺乏空間歸納偏差的重新采樣器在將來自多個視覺編碼器的串聯標記壓縮為有限數量的可學習查詢時存在困難。

空間歸納偏差和LLM與視覺特征之間的深度互動有助於更好地聚合和壓縮視覺特征.
指令調優數據
收集了所有可用的指令調優數據,並透過增強多樣性、平衡來源和改進混合方式來進行數據整理。

內圈顯示的是Cambrian-10M 的原始分布情況。外圈顯示的是經過策劃的Cambrian-7M。右圖Cambrian數據集中的所有資料來源以及在數據整理中篩選出的資料來源。
數據收集
Cambrian-10M 透過從現有資料來源收集指令調優數據和定向互聯網數據收集引擎,建立了一個大規模的指令調優數據池,稱為Cambrian-10M。該數據池包含約9784k條數據。
數據整理
Cambrian-10M是一個大型的指令調優數據池,來源多種資料來源,各類別數據比例不均。在此,透過改善數據平衡和調整數據比例來研究數據整理。 數據平衡 設定單一資料來源數據點數量的閾值。為了研究的數量效應,我們繪制了從尾到頭按數量排序的條目累積和。在本節中選擇了150、250、350和450的閾值,——發現250和350之間的閾值對Cambrian-10M效果最好。
數據比例 進行了固定數據集規模為1350k的初步實驗,檢查了不同數據比例對下遊效能的影響。
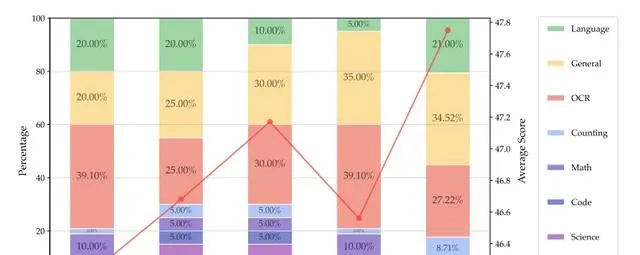
(i) 平衡一般、OCR和語言數據至關重要。模型的OCR能力與OCR數據比例成正比,但過高的OCR比例會損害一般VQA和視覺中心的效能。(ii) 知識密集型任務的效能受多種因素影響,通常需要OCR、圖表、推理和一般感知的混合。增加科學數據比例有幫助,但比例過低會導致效能差。 Cambrian-7M 透過套用確定的數據比例對Cambrian-10M進行數據過濾,建立了一個更小但品質更高的數據集Cambrian-7M。

指令調優方法
MLLMs以預訓練的LLM和視覺骨幹為起點,透過投影器(MLP)等連結器連線這些模組。最初的LLaVA提出了一個兩階段凍結訓練過程:首先,使用介面卡數據(如基於標題的VQA)在凍結的LLM和視覺骨幹之間預訓練連結器,然後在凍結視覺編碼器的情況下,使用指令調優數據對連結器和LLM進行微調。在此,透過廣泛實驗重新審視這個話題。
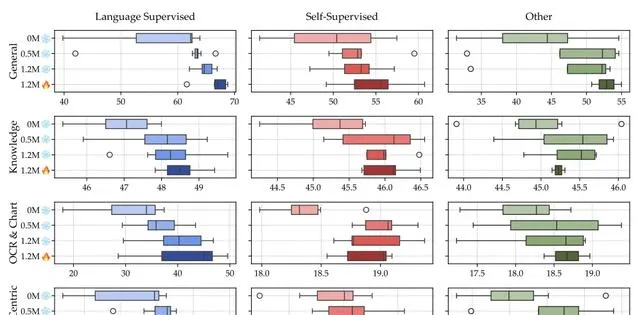
顯示了不同訓練方案和視覺編碼器型別(語言監督、自監督和其他)的基準測試得分在基準測試類別中的分布。這四種訓練方案包括凍結視覺編碼器並使用不同數量的介面卡數據(0M、0.5M、1.2M),以及解凍視覺編碼器並使用1.2M介面卡數據。
單階段與兩階段訓練
最近的研究提倡跳過連結器預訓練,聲稱這「減少了計算成本而不損害下遊效能。」為了探討這一說法是否成立——特別是在使用非語言監督的視覺編碼器時——我們進行了使用0、0.5M和1.2M介面卡數據的實驗。
兩階段訓練是有益的;更多的介面卡數據進一步提高了結果。
凍結與解凍視覺編碼器
在微調過程中,凍結或解凍視覺骨幹的做法也各不相同,一些人認為解凍視覺骨幹會顯著降低效能。
解凍視覺編碼器是廣泛有益的。語言監督模型總是受益;SSL模型在視覺中心的基準測試中特別受益。
基準測試
當前的MLLMs主要依賴於CLIP作為視覺編碼器,因為它與語言的預對齊以及容易適應LLM的token空間。然而,強大的語言先驗知識是一把雙刃劍——它們彌補了學習有效視覺表示的不足,同時減少了從廣泛的視覺表示學習研究中獲得的見解。。

左圖:不同基準測試中啟用和禁用視覺輸入的MLLM效能比較。基準測試按啟用和禁用視覺輸入的平均得分差異排序。右圖:基於效能指標的主成分分析顯示了基準測試的聚類。我們將這些聚類分別標記為綠色的「通用」、黃色的「知識」、紅色的「圖表和OCR」、以及藍色的「視覺中心」。
是誰在回答問題:LLM還是MLLM?
比較了有無視覺輸入情況下MLLMs的表現,並計算了隨機猜測的預期得分。
SQA-I3、MMMU、MathVista和AI2D在視覺啟用和禁用之間顯示出不到5%的差距,表明這些基準測試可能不顯著依賴視覺輸入,而是嚴重依賴基礎LLM。TextVQA和GQA在隨機猜測和視覺禁用得分之間表現出近40%的正差距,暗示這些基準測試存在強烈的語言偏見。另一方面,基準測試如MMVP和MME Perception在視覺禁用時的表現明顯低於隨機猜測,表明強大的視覺基礎特別重要。
基準分組
為了更好地理解MLLM效能的不同方面,分析了23種MLLM在每個基準測試上的效能之間的相關性。
對基準測試得分進行主成分分析,並觀察到形成了對應於「通用」、「知識」、「圖表和OCR」和「視覺中心」類別的集群。
大多數基準測試不能正確測量視覺中心能力,而那些能夠測量的基準測試樣本非常少。
CV-Bench
為了解決現有視覺中心基準測試的局限性,引入了Cambrian Vision-Centric Benchmark(CV-Bench)。Cambrian-1以視覺為中心的基準測試(CV-Bench)中評估的二維和三維任務細目如下:

現有的視覺基準測試可以有效地改編為VQA問題,從而能夠評估視覺中心的MLLM能力。












