本文內容來源於【測繪學 報】2023年第10期( 審圖號GS京(2023)1931號 )
顧及空間多尺度鄰域效應和時間依賴性的城市擴充套件模擬
王海軍 1,2 , 常瑞寒 1 , 李啟源 1 , 周曉艷 1 , 王權 1 , 曾浩然 1 , 劉一寧 2,3 , 嶽照溪 2,3
1. 武漢大學資源與環境科學學院, 湖北 武漢 430079;
2. 自然資源部超大城市自然資源時空大數據分析套用重點實驗室, 上海 200063;
3. 上海市測繪院, 上海 200063
基金計畫: 自然資源部超大城市自然資源時空大數據分析套用重點實驗室開放基金(KFKT-2022-10);國家自然科學基金(42171411)
摘要 :在推進新型城鎮化和實施新時代國土空間規劃的戰略背景下, 城市擴充套件研究逐漸成為熱點問題。當前基於元胞自動機(CA)的城市擴充套件模擬對城市空間多尺度鄰域效應解析不足, 且在轉換規則中對城市長時間演變過程的時間依賴性影響表達不夠完善, 簡化了城市擴充套件的時空依賴性, 無法真實模擬推演未來規劃實施情景以服務於國土空間規劃。針對上述問題, 本文構建一種兼顧空間多尺度鄰域效應(3DCNN)和時間依賴性(ConvLSTM)的城市擴充套件深度學習CA模型(下文稱「Deep-CA」)。首先透過組合普通摺積和空洞摺積的3DCNN來提取城市空間多尺度鄰域效應, 再利用ConvLSTM神經網路將歷史資訊同化, 考慮長時間序列的時間依賴性, 從而得到城市擴充套件的適宜性機率。北京市1995—2015年的土地利用數據及其驅動因質數據用於驗證所提CA模型的科學性與適用性, 1995—2010年數據用於模型訓練, 模擬2015年的城市範圍。同時將模擬結果精度與ANN-CA、LR-CA和ME-CA 3種傳統方法進行對比。與傳統CA模型相比, Deep-CA的北京市2015年模擬FoM指數提高了4%左右, 且對於城市全域和局部形態模擬效果較好, 斑塊破碎度低。試驗結果表明, Deep-CA可以準確獲取長期時空依賴關系, 從而進一步提高城市擴充套件CA模型的模擬真實性。
關鍵詞 :城市擴充套件 空間多尺度鄰域效應 時間依賴性 深度學習 元胞自動機
引文格式: 王海軍, 常瑞寒, 李啟源, 等. 顧及空間多尺度鄰域效應和時間依賴性的城市擴充套件模擬[J]. 測繪學報,2023,52(10):1772-1783. DOI: 10.11947/j.AGCS.2023.20220244
WANG Haijun, CHANG Ruihan, LI Qiyuan, et al. Considering the spatial multi-scale neighborhood effect and time dependence into cellular automata model for urban growth simulation[J]. Acta Geodaetica et Cartographica Sinica, 2023, 52(10): 1772-1783. DOI: 10.11947/j.AGCS.2023.20220244
閱讀全文 :http://xb.chinasmp.com/article/2023/1001-1595/20231015.htm
引 言
近幾十年來,全球範圍內普遍出現高速城鎮化現象,土地城鎮化速度遠大於人口城鎮化速度,城鎮用地無序蔓延且集約利用程度低,生態環境退化、自然資源枯竭和耕地破壞更是時有發生 [1 -2 ] 。新時代國土空間規劃亟須真實模擬推演未來規劃實施情景,以便對國土空間利用進行評估及最佳化調控。因此,更加準確地模擬土地利用變化過程並深入理解土地利用變化時空模式對於土地管理者和城市規劃決策者是必不可少的 [3 ] 。元胞自動機因其開放式的結構,可以與其他模型整合耦合來進行復雜非線性系統的時空演變的模擬 [4 ] ,在城市擴充套件和土地利用演變模擬中取得了顯著成就 [5 -6 ] 。
研究人員提出一系列基於元胞自動機(cellular automata, CA)的模型用於城市擴充套件模擬,與機器學習耦合使用的學習模型包括支持向量機-元胞自動機(SVM-CA)、人工神經網路-元胞自動機(ANN-CA)、地理加權人工神經網路-元胞自動機(GWANN-CA)和隨機森林-元胞自動機(RF-CA) [7 -10 ] 等,這些方法能夠有效挖掘城鎮擴充套件的非線性特征,從而構建其非線性驅動機制,有助於提高模擬精度; 此外,還有邏輯回歸-元胞自動機(LR-CA)、CA-Markov和最大熵-元胞自動機(ME-CA)等機理模型 [11 -12 ] ,對獲得的驅動機制有明確解釋,但對城市擴充套件過程的非線性特征解釋不足。以上這些CA模型共同存在一些不足,難以實作CA對城市擴充套件的真實模擬,不足之處主要體現在:①模型構建時對鄰域空間的多尺度特征表達不足。城市土地元胞狀態的變化不僅僅受到自身單個元胞資訊的影響,相鄰元胞的空間變量資訊也在不同尺度上透過不同的特征效應影響元胞狀態的改變,少有研究完整地表達城市土地利用演變的多尺度空間鄰域效應影響。②轉換規則的構建沒有顧及長時間序列的時間依賴性影響,即沒有考慮城市歷史空間變量影響(時間依賴性)。城市土地利用變化從歷史過程上看,是具有趨勢性的,受政治、經濟、自然、文化等歷史因素的影響,目前學者對城市擴充套件模擬多基於馬可夫過程,認為城市擴充套件僅受上一時態土地利用及驅動因素影響 [13 ] ,對長時序下的時間依賴性挖掘不足。
具有深度和廣度的神經網路,作為機器學習的一個子領域,被稱為深度學習(deep learning, DL),逐漸在城市擴充套件模擬中得到重視。摺積神經網路(convolutional neural network, CNN)是一種深度學習網路,它可以考慮空間效應,透過摺積運算提取局部驅動因子空間特征,從而獲得準確土地利用演變結果 [14 ] 。文獻[15]耦合多驅動因子構建元胞多維向量,提出了顧及空間鄰近地塊間驅動效應的CNN-VCA(vector-based cellular automata)模型。針對土地利用演化的多尺度特性,文獻[16]提出基於多結構摺積神經網路(multi-structure convolutional neural network, MSCNN)的MSCNN-CA模型,相比單結構摺積神經網路CA模型具有更高的準確度和穩健性,但多結構摺積使得參數量成倍增多,效率不高。目前有學者透過構造不同大小摺積核從驅動因子層面提取城市擴充套件的空間多尺度鄰域效應,還有學者透過構建雙尺寸鄰域 [17 ] 來解決鄰域大小選擇的矛盾,但都只考慮了單一時態下的空間多尺度鄰域效應; 三維摺積神經網路(three-dimensional convolutional neural network, 3DCNN)是CNN的擴充套件,透過增加摺積核的維度,可以對多期城市擴充套件相關數據沿著時間維度進行空間資訊的提取,本文擬將元胞的近鄰範圍空間變量和非近鄰空間變量對元胞狀態改變的不同空間效應資訊(多尺度)挖掘融合,從而使轉換規則的提取更加可靠。長短期記憶(long short term memory, LSTM)是另一種深度神經網路,可以穩定地捕獲長期模式,讓需要的歷史資訊傳遞下去,從而避免了「梯度問題」 [18 ] 。摺積長短期記憶(convolution LSTM, ConvLSTM) [19 ] 是全連線LSTM的改進版,將全連線運算子替換為摺積運算子,在將歷史資訊過濾傳遞下去的同時,保留了數據即二維影像的空間資訊,適用城市擴充套件模擬所需時空資訊的提取融合。
綜上,本文提出一種顧及空間多尺度鄰域效應(3DCNN)和時間依賴性(ConvLSTM)的城市擴充套件深度學習CA模型(下文稱「Deep-CA」),透過組合普通摺積和空洞摺積的3DCNN沿時間維度挖掘不同空間尺度下的鄰域效應,普通摺積層用於提取建模元胞的近距離空間鄰域效應,而空洞摺積透過設定間隔的方式可以獲得更大的鄰域範圍,在保證模型執行效率的同時,最終實作元胞多尺度鄰域特征的聚合。對挖掘得到的空間特征圖透過ConvLSTM實作時間和空間資訊的過濾融合, 得到影響未來城市土地利用變化的時空依賴性資訊,經由全連線網路,得到城市擴充套件的轉換規則。該模型使得CA轉換規則的挖掘提取更加完善可靠,為城市擴充套件提供更加準確可靠的模擬方法。
1 研究區與數據集
北京市是中國的首都、直轄市、國家中心城市、超大城市,國務院批復確定的中國政治中心、文化中心、國際交往中心、科技創新中心,吸引了大量人口流入,城鎮化行程迅速,其位置如圖 1(a)所示。截至2020年,全市下轄16個區,總面積16 410.54 km 2 。根據第七次人口普查數據,截至2021年末,北京市常住人口為2 188.6萬人。近幾十年來,由於交通的不斷改善和政府政策的推出完善,北京市經濟快速發展,人口不斷增加,城市迅速擴充套件(圖 1(b)),不可避免產生交通擁堵、環境惡化、住房困難等「大城市病」。為了遏制城市無序蔓延,集約節約利用土地,有必要了解城市擴充套件的時空依賴性對城市土地演變的影響,有利於真實展現城市未來用地變化,為政府合理規劃城市新用地、限制城市用地盲目增長提供借鑒。
|
圖 1 北京市位置和1995—2015年每5年城市擴充套件 Fig. 1 The location of Beijing and the urban growth of Beijing each five-years period from 1995 to 2015 |
|
圖選項 |
圖 1(b)為1995—2015年的北京市城市用地擴充套件圖。相關研究表明,制度結構、社會經濟因素、人口密度、鄰裏因素和鄰近性等是城市擴充套件的主要驅動因素 [20 -22 ] 。因此,結合研究區實際情況及數據的可得性,本文選取11個驅動因素來構建城市擴充套件模型,其中DEM和坡度數據用於表征地表狀況;GDP和人口密度(population, POP)表征社會經濟因素;道路、城市土地和POI數據用於計算鄰近效應,得到距城市用地距離、距國道距離、距省道距離、距縣道距離、距高速距離、距鐵路距離、距縣級行政中心距離7個基於距離的驅動變量。所有城市增長驅動變量處理和視覺化(圖 2)在ArcGIS 10.7中進行。本文所需數據及其處理說明見表 1,包括土地利用數據、POI數據、交通道路數據、社會經濟數據和DEM數據等。1995—2015年,每5年為一個時期。社會經濟封包括GDP和人口,DEM數據用於計算坡度和高程,道路和POI數據用於獲得歐氏距離變量數據。所有數據柵格化後均被重采樣至30 m的空間分辨率,且保持座標、投影和位置一致。北京市用地型別分為城市、非城市用地和水域3類用地。

|
| 圖 2 北京市城市擴充套件驅動因素 Fig. 2 Driving factors of urban growth in Beijing |
|
圖選項 |
表 1 數據集 Tab. 1 Dataset

表選項
2 研究方法
本文具體研究思路為:①使用普通摺積和空洞摺積組合的3DCNN沿時間維度挖掘不同空間尺度下的鄰域效應,普通摺積層用於提取建模元胞的近距離空間鄰域效應,而空洞摺積透過其設定間隔的方式可以獲得更大的鄰域範圍,在保證模型執行效率的同時,實作多尺度鄰域特征的聚合。②將得到的空間多尺度鄰域特征圖進一步提取得到影響未來城市土地利用變化的時間依賴性資訊。本文透過構建ConvLSTM神經網路挖掘時間依賴性資訊,最終輸出時空資訊同化的特征圖;將提取融合的最終資訊輸入全連線層,得到元胞轉換機率。③深度學習網路與CA基本框架耦合,構建顧及空間多尺度鄰域效應和時間依賴性的時空CA模型。
2.1 深度學習模型
2.1.1 3DCNN用於空間多尺度鄰域效應提取
3DCNN沿著時間和空間維度進行3D摺積運算,由於在電腦視覺研究中很少考慮時間維度,城市土地利用演變模擬時也很少充分考慮時間維度,導致它不像2DCNN那樣套用廣泛 [23 ] ,但是3DCNN已被證實更加適合時空呈現 [24 ] 。土地利用遙感數據及其驅動數據通常包含時空資訊(特征),3DCNN可以有效挖掘利用這些資訊(特征)。例如,城市不同時期的道路因素都會對未來城市土地利用變化產生一定影響。3DCNN可沿著時間維度對空間資訊進行特征提取,非常適合用於城市擴充套件空間特征挖掘,同時,它的特征提取能力也更加可靠強大。
3DCNN的摺積層網路的摺積運算如式(1)所示 [25 ]
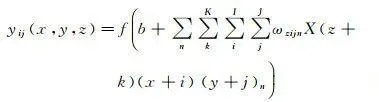 (1)
(1)
式中, f 為啟用函式; b 為偏置; y ij ( x , y , z )為摺積層輸出值; K 、 I 、 J 為摺積核維度,其中 I 、 J 分別表示核的寬度和高度, K 為沿時間維度的核大小; ω zijn 為上一摺積層或池化層輸出的第 n 個特征圖上( K , I , J )位置所對應的權重; X 為輸入的三維數據。
從特定特征圖局部鄰域提取特征由3D摺積濾波器執行,並添加偏置,結果加啟用函式。
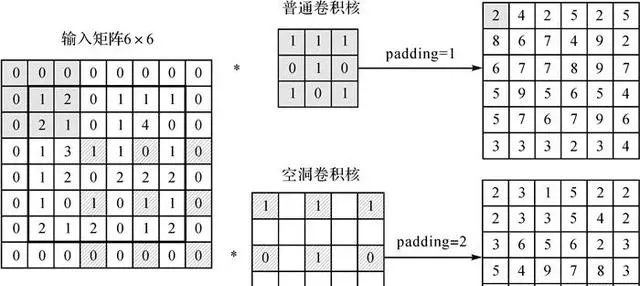
在本文提出的模型中,3DCNN透過組合使用普通摺積和空洞摺積,從城市擴充套件驅動因素中提取空間多尺度鄰域效應;兩者的二維運算結構如圖 3所示,普通摺積層用於提取土地元胞的近距離空間鄰域效應,空洞摺積以設定間隔的方式將摺積計算作用於非連續空間單元,擴大鄰域效應範圍,實作多尺度鄰域效應的聚合。實際生活中,時間影像(視訊)是由多光譜(多波段)通道組成,維度包括空間、時間和光譜維度,類比到本文為空間、時間和驅動因子個數,由此所需數據型別為4D張量,由於深度學習模型訓練分批次進行訓練,因此添加一個batch(批)維度,最終模型輸入數據為「批尺寸×時間×特征×高度×寬度」的5D張量,形狀為( b , t , c , h , w ),本文中批次最終設定為32,數據期數為4,驅動因子個數11,影響元胞空間大小為31×31,即(32, 4, 11, 31, 31)。
|
| 圖 3 普通摺積和空洞摺積運算 Fig. 3 Ordinary convolution and hole convolution operations |
|
圖選項 |
2.1.2 歷史時空資訊同化的ConvLSTM網路
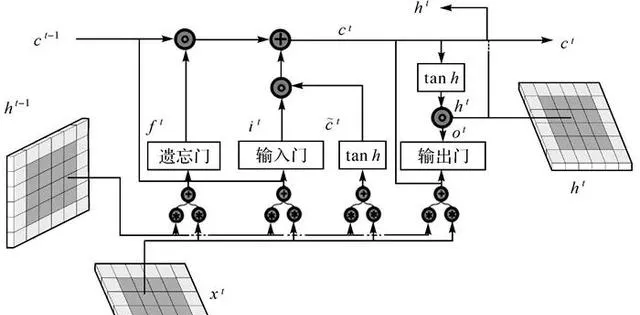
LSTM網路可以保持早期觀察序列中的相關資訊,同時消除不相關資訊,更重要的是,它克服了傳統模型存在的過度擬合、梯度爆炸和消失問題 [18 ] 。LSTM網路將展平的特征圖作為輸入,透過全連線的層進行編碼,不可避免遺失了空間相關資訊。ConvLSTM將LSTM中的全連線運算子替換為摺積運算子(圖 4),保證空間特征圖大小不變,進行時空資訊的過濾融合輸出,以更少的參數為模型增加了更多的計算能力。ConvLSTM的體系結構可以表達為式(2)—式(7) [19 ]
|
| 圖 4 摺積LSTM基本結構 Fig. 4 The basic structure of ConvLSTM |
|
圖選項 |
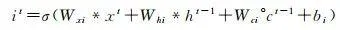 (2)
(2)
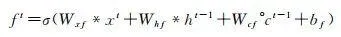 (3)
(3)
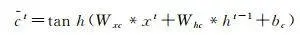 (4)
(4)
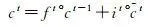 (5)
(5)
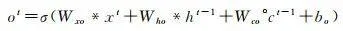 (6)
(6)
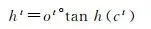 (7)
(7)
式中,*為摺積算子; σ 為sigmoid啟用函式;°表示哈達瑪積,單元狀態由 c 1 , c 2 ,…, c t 表示,隱藏狀態由 h 1 , h 2 ,…, h t 表示; i t 、 f t 、 o t 分別表示輸入門輸出門和遺忘門輸出結果; W xi 、 W hi 、 W ci 、 W xf 、 W hf 、 W cf 、 W xo 、 W ho 、 W co 、 W xc 和 W hc 為二維摺積核權重; b i 、 b f 、 b c 和 b o 是偏置項。
2.2 城市擴充套件時空CA模型構建(Deep-CA)
本文使用深度學習模型(即3DCNN-ConvLSTM)預測2010—2015年北京市非城市變為城市用地的轉換機率,最終獲得開發適宜性圖層匯入CA模型中進行城市擴充套件模擬。CA模型中元胞的最終轉換機率由式(8)計算得出(由於後續試驗中涉及不同模型精度對比,暫不將隨機效應納入轉換規則)
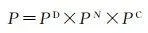 (8)
(8)
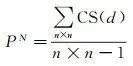 (9)
(9)
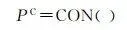 (10)
(10)
式中, P 為最終轉換機率; P D 是深度學習模型考慮歷史驅動因素得到的開發適宜性機率; P N 表示鄰域配置的影響,用於約束城市形態和接收周圍元胞影響 [17 ] ; n 表示鄰域大小; d 表示領域單元與中心單元之間的距離( d =1, 2, 3, …, ( n +1)/2);CS( d )表示距離為 d 時的鄰域單元狀態函式,如果元胞狀態為城市則返回1,否則,返回0; P C 為約束因素,當元胞為城市元胞或為水域元胞時,CON()返回0,其他,返回1。
2.3 評價指標
為了評估模擬的城市擴充套件準確度,參考相關文獻,選擇整體準確度(overall accuracy, OA)、Kappa系數 [26 ] 和品質因數(figure of merit, FoM) [27 ] 來評估所提出的CA模型的模擬能力,OA、Kappa和FoM的取值範圍均在0~1之間,其值越大,模擬結果越好。其中,Kappa系數是衡量土地利用模擬與觀測之間數量一致性的常用方法;FoM側重於衡量模擬和觀測之間變化一致性的高低。命中率h(表示模擬為城市元胞且實際為城市元胞的數目占元胞總數的比例)和錯誤率 c (表示模擬為非城市元胞但實際為城市元胞的數目占元胞總數的比例)也將用於模型評價。OA、Kappa和FoM的計算公式分別為
(11)
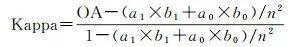 (12)
(12)
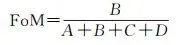 (13)
(13)
式中,right為模擬正確的元胞數量; n 為所有元胞的總數量; a 0 和 a 1 分別為觀測結果中城市元胞和非城市元胞的數量; b 0 和 b 1 分別為模擬結果中城市元胞和非城市元胞的數量; A 為觀測為變化但模擬為保持不變的元胞數量; B 為在觀測和模擬中均為城市擴充套件的元胞數量; C 為觀測為城市擴充套件但模擬為其他地類轉換的元胞數量,本文只考慮非城市向城市用地的轉變,則 C 為0; D 為觀測為非城市但模擬為城市擴充套件的元胞數量。
此外,還使用一組景觀指數來評估實際和模擬城市土地之間的景觀格局相似性,從密度大小及差異、鄰近度指標、形狀指標和面積指標分別選擇斑塊數量(number of patches,NP)、平均歐幾裏得最鄰近距離(Euclidean nearest neighbor index, ENN_MN)、平均形狀指標(shape index, SHAPE_MN)和最大斑塊占景觀面積比(largest patch index, LPI)共4個景觀指標 [28 -29 ] ,其中NP用於衡量斑塊數量,ENN_MN衡量斑塊分布,SHAPE_MN衡量斑塊形狀復雜度,LPI表征主要斑塊優勢度,所有景觀指標透過Fragstats 4.2計算 [30 ] 。相似性計算公式 [31 ] 為
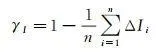 (14)
(14)
(15)
式中, I si 和 I oi 分別為模擬城市土地和實際城市土地的第 i 個景觀指標的值;Δ I i 為第 i 對模擬和實際景觀指標的歸一化差,LPI的原始單位已經是百分比,因此LPI的Δ I i 為差的絕對值; γ I 為實際和模擬城市土地之間的景觀格局相似性; n 為景觀指標的個數;ENN MN 為平均歐幾裏得最鄰近距離;SHAPE MN 為平均形狀指標。
3 試驗與分析
3.1 模型結構及試驗細節
Deep-CA模型的構建和執行均在Python 3.7環境下實作,Pytorch作為後端 [32 ] ,同時也使用了Numpy、Visdom和Gdal等Python庫。電腦配置為Intel i7-10代,16 GB記憶體,4 GB GTX 1650 Ti顯卡,模型訓練和執行采用GPU並列加速。對於訓練過程,測試了16、32和64的不同批次處理以提高模型效能,發現批大小為32時訓練效果最好,且發現模型至少叠代90次才能收斂,為了保證模型的精度和效率,訓練代數最終設定為110。選擇了學習率為0.000 1的Adam最佳化器 [33 ] ,和交叉熵 [34 ] 作為損失函式,並在驗證集上使用提前停止法(Early Stopping)防止模型過度擬合,即泛化能力過低。經過多次偵錯,模型最終結構如圖 5所示,模型結構中,加入批標準化層和Dropout正則化層,也可起到防止過擬合的作用。模型的訓練曲線如圖 6所示,在早期,可以看到驗證集準確度迅速提高,在達到0.95左右時,準確度的變化會減慢,但仍繼續增加,達到的最高準確度為0.975,也是模型的提前停止點;損失函式值隨著代數增加整體下降,表示誤差逐漸最小化。
| 圖 5 Deep-CA模型結構 Fig. 5 The structure of Deep-CA model |
|
圖選項 |
| 圖 6 Deep-CA模型訓練曲線 Fig. 6 Training curve of the Deep-CA model |
|
圖選項 |
模型結構為3DCNN、ConvLSTM、全連線層和CA的組合,以提高城市模擬的精度。ConvLSTM連線到3個3DCNN塊,3DCNN沿著時間維度在不同摺積尺度上進行嚴格的空間特征提取,3DCNN對輸入的樣本影像執行多步摺積、批標準化和最大池化操作,將提取得到的空間多尺度鄰域特征圖輸送到ConvLSTM塊,ConvLSTM接收到特征圖後,執行更嚴格的時空特征提取。最後,最終特征圖展平以後被輸入到具有512個神經元全連線層,經過多個全連線層輸出最終機率值。層與層之間使用機率為0.5的dropout層 [35 ] ,以避免過度擬合。將綜合得到的機率圖(式(8))輸入CA模組中,多次叠代,每次叠代按照變化元胞個數從已排序的機率中找到元胞是否變化的閾值作為判斷條件。
本文選擇北京市20年數據(1995—2015年,每5年為一期)進行模型的訓練驗證,1995—2010年數據用於訓練,2015年數據用於測試訓練的模型。為了避免空間自相關影響以及兼顧模型的效率和效能,隨機抽樣30 000個樣本,正負樣本各占50%,其中樣本集80%用於訓練,余下20%驗證集用於調整模型超參數和檢查停止條件。
為了驗證所提模型的優勢,本文選擇了代表機理CA模型的LR-CA、ME-CA和代表學習模型的ANN-CA與本文的Deep-CA進行比較,這些模型均選擇北京市2010和2015年數據,未考慮空間效應和時間依賴性。本文各CA模型最終參數設定如下:轉換機率為各模型得到的開發適宜性圖集;半年叠代一次,2010—2015年共叠代10次;鄰域選擇7×7的莫耳型鄰域;生態規劃限制設定為水體不能被侵占;本文不考慮隨機擾動因素影響。
3.2 模型對比分析
表 2列出了傳統模型LR-CA、ME-CA、機器學習ANN-CA與顧及空間多尺度鄰域效應與時間依賴性的Deep-CA在測試數據(2015年)上的預測結果。
表 2 2015年北京市城市擴充套件模型模擬精度評估 Tab. 2 Simulation accuracy evaluation of Beijing urban growth model in 2015
表選項
表 2表明,與其他模型相比,Deep-CA模型明顯提高了模擬精度,各個指標都有不同程度提高, 特別是FoM達到0.304,提高了約4%,從而驗證了時空依賴性對城市擴充套件具有重要影響。模型精度沒有提升過高原因推測為反映歷史情況的驅動數據不夠完善,道路數據只有近期道路,存在雜訊影響情況,但Deep-CA可以在學習過程中辨識雜訊並加以修正或剔除,從而保證模型精度,從這裏也可以看出Deep-CA強大的學習能力。
本文還結合NP、ENN_MN、SHAPE_MN和LPI 4個景觀指標,評價了模擬城市土地與實際城市土地的全域景觀相似性。表 3顯示了4個模型的景觀相似度的計算結果。與ANN-CA、ME-CA和LR-CA相比,Deep-CA模型與實際城市土地的景觀相似性最高(0.871),說明Deep-CA對城市形態有更好的控制。
表 3 2015年北京市不同模型的模擬結果的景觀指數 Tab. 3 Landscape indices of the simulated results based on different models for Beijing in 2015
|
|
圖 7左側顯示了北京市2015年Deep-CA的模擬結果,為了更直觀展示不同模型模擬結果局部差異,兼顧城市擴充套件型別,在研究區選擇6個不同大小的局部區域,將各個模型得到的模擬結果與實際結果進行對比。可以看出Deep-CA對城市增長有更精細的控制,模擬結果邊緣更接近現實,證明了空間多尺度鄰域效應和時間依賴性對城市增長形態的影響。具體來看,對於填充式城市擴充套件(圖 7(a)、(d)),Deep-CA效果最好,ME-CA次之,LR-CA和ANN-CA仍為邊緣式擴充套件,填充不夠徹底;由圖 7(b)、(c)、(e)、(f)可看出,Deep-CA對城市邊緣約束更好,未出現盲目沿城市邊緣擴充套件情況。
| 註:(1)為實際城市擴充套件,(2)—(5)分別為使用Deep-CA、ME-CA、ANN-CA、LR-CA得到的模擬結果。圖 7 模擬結果與實際的局部對比 Fig. 7 Local comparison between the simulated results and reality |
|
圖選項 |
4 結論與討論
本文提出了一種結合深度學習提取空間多尺度鄰域效應和長時間序列時間依賴性特征的城市擴充套件元胞自動機模型(Deep-CA)。3DCNN和ConvLSTM首次用於城市擴充套件模擬,拋開了城市擴充套件模擬的Markov假設前提,即只關註研究時間段的起點和終點,將長時間序列數據的時間依賴性特征考慮進城市擴充套件模擬。3DCNN沿著時間維度在不同摺積尺度上進行嚴格的空間鄰域特征提取,ConvLSTM對3DCNN提取空間特征圖進行更嚴格的時空特征提取,對時間和空間資訊進行同化輸出,從而更加準確仿真城市土地利用變化。以北京市作為研究區,驗證所提出的Deep-CA模型效能。試驗表明,與傳統模型相比,從模擬精度上看,Deep-CA模型的預測準確率最高,OA為0.971,Kappa系數為0.855,FoM指數為0.304, h 為1.28%, c 為1.46%;從構建的景觀格局相似性上看,Deep-CA景觀相似性最大,為0.871;從模擬局部形態上看,Deep-CA填充式擴充套件模擬效果最好,對城市邊緣形態約束也更優。綜上,與其他CA模型(LR-CA、ANN-CA和MN-CA)相比,Deep-CA模型能夠獲得最佳的仿真結果。
本文所提出的Deep-CA模型需要在長時間土地利用數據和驅動因子數據支撐下使用,受電腦記憶體限制,研究區尺度為市域,未來可以最佳化演算法或擴大執行記憶體使其可以在更大尺度上進行模擬。Deep-CA模型同樣存在其局限性:①由於考慮歷史因素致使數據整合倍增加,考慮電腦效能,驅動因素不能過多選擇,未來可以適當加入其他重要因素,如距車站距離、距醫院距離、距停車場距離等基於POI獲得的變量。②該模型屬於深度學習模型,雖然可以很好捕捉城市擴充套件的非線性特征,但無法像機理模型解析各個驅動因子對城市擴充套件的影響程度。使用更加完善的驅動因質數據以及解析城市擴充套件機理將成為下一步工作的重點。③城市擴充套件受城市規劃和政府政策的影響,將政策融入到Deep-CA模型中也是未來工作之一。
作者簡介
第一作者簡介: 王海軍(1972—), 男, 博士,教授,主要從事地理模擬、國土空間規劃、城市規劃和土地資源評價研究。E-mail:[email protected]
通訊作者: 常瑞寒, E-mail: [email protected]
初審:張艷玲
復審:宋啟凡
終審:金 君
資訊











