本文內容來源於【測繪學報】2024年第
4
期(
審圖號GS京(2024)0714
號)
結合SAM大模型和數學形態學的歷史地圖水系資訊提取方法
趙飛 ,1,2 , 李兆正 3 , 甘泉 4 , 高祖瑜 3 , 王湛初 3 , 杜清運 5 , 王振聲 6 , 沈洋 4 , 潘威 ,7
1. 雲南大學地球科學學院,雲南 昆明 650500
2. 雲南省中老孟緬自然資源遙感監測國際聯合實驗室,雲南 昆明 650051
3. 雲南大學國際河流與生態安全研究院,雲南 昆明 650500
4. 自然資源部第三大地測量隊,四川 成都 610100
5. 武漢大學資源與環境科學學院,湖北 武漢 430079
6. 鵬城實驗室戰略與交叉前沿研究部,廣東 深圳 518055
7. 雲南大學歷史與檔案學院,雲南 昆明 650091
第一作者簡介: 趙飛(1986—),男,博士,副教授,研究方向為地圖學理論與套用、時空大數據分析。E-mail:[email protected]
通訊作者: 潘威 E-mail:[email protected];[email protected]
基金計畫: 國家社科基金重大計畫(22&ZD225);國家自然科學基金(41961064);四川省測繪地理資訊局2023年新型基礎測繪技術研究補助計劃(2023KJ001);鵬城實驗室重大計畫(PCL2023AS6-1)

摘要: 歷史地圖記載著豐富的歷史地理資訊,能夠幫助了解歷史規律,為當代發展提供借鑒。不同於現代地圖、遙感影像等數據,歷史地圖保存時間久,存在留存數量少、影像精度低等問題,地圖符號也與現代有所差異,因此資訊難以被高效提取。針對該問題,本文以歷史地圖【寧夏省境黃河沿岸溝渠水道地形圖】為試驗數據,提出一種智慧化歷史地圖水系資訊提取方法。首先,結合符號句法,運用聚類與數學形態學方法構建數據集;然後,改進通用大模型(SAM)結構並進行遷移學習最佳化權重;最後,借助改進SAM自動提取歷史地圖水系資訊。將試驗結果與其他模型作對比,顯示本文方法提取結果邊界清晰,輪廓完整,準確率、精度等指標均為最高。同時,將提取結果與該區域水系現狀作對比,發現歷史上的河流溝渠如今大多改道、偏移或消失,湖泊面積大大減小。本文方法基於SAM通用大模型進行改進,驗證了大模型在地圖領域的可用性,為地圖資訊提取提供了思路。
關鍵詞:
本文參照格式
趙飛, 李兆正, 甘泉, 高祖瑜, 王湛初, 杜清運, 王振聲, 沈洋, 潘威. 結合SAM大模型和數學形態學的歷史地圖水系資訊提取方法[J] . 測繪學報, 2024, 53(4): 761-772 doi:10.11947/j.AGCS.2024.20230308
ZHAO Fei.
全文閱讀
http://xb.chinasmp.com/article/2024/1001-1595/1001-1595-2024-04-0761.shtml
歷史地圖借助符號實作資訊承載和空間顯示的功能,記載的歷史地理資訊能夠幫助學者更好地了解地理要素時空演變,從古至今都是人們認知生存環境的重要工具[1-3] 。歷史地圖不同於普通地圖,其資訊提取主要面臨以下困難:①歷史地圖本身留存數量少,屬於小樣本數據;②影像精度低,顏色失真;③歷史地圖與現代地圖在符號句法方面存在差異[4] 。上述3點使得普通地圖的資訊提取方法在歷史地圖上效果欠佳,需要在考慮歷史地圖特點的基礎上進行最佳化。
地圖資訊提取方法可分為傳統方法和深度學習方法。傳統方法包括特征聚類[5-14] 和基於灰度值的元素提取[15-19] 。在使用聚類方法的研究中,文獻[6]透過分析影像的彩色空間,確定特征數目並透過聚類進行地圖要素提取。文獻[10]將影像的空間與顏色資訊組合成特征向量,輸入聚類演算法中進行顏色分割與要素提取。文獻[13]基於分層減法聚類提出了一種快速模糊聚類方法,在聚類數目很多的情況下能夠明顯提高聚類速度。在基於灰度值的提取研究中,文獻[15]透過分析地圖符號在灰度影像中的灰度值表面模型,提出基於灰度變換的線段跟蹤方法提取地圖要素。文獻[19]基於灰度值提出能量密度的概念,依靠線狀與面狀要素的能量密度差異區分線狀與面狀符號,再借助Shear變換進行提取。傳統方法精度尚可,但操作煩瑣,參數設定復雜,只適用於少量地圖資訊提取。深度學習方法一般套用摺積神經網路(convolutional neural network,CNN)對地圖進行辨識。CNN具有多層非線性對映的深層結構,可以實作復雜的函式逼近,在影像特征提取領域十分有效,經過簡單訓練便可進行要素提取和地圖辨識[20-21] 。文獻[22]將CNN與特征金字塔網路結合進行地圖要素多尺度檢測。文獻[23]在CNN基礎上加入摺積註意力模組,進行地圖註記辨識和文字要素提取。文獻[24]手動標註圖例數據集,借助小樣本學習模型Keras-Oneshot進行地圖圖例辨識。文獻[25]利用地物圖片構建小樣本數據集,使用VGG16在ImageNet數據集上的預訓練模型進行遷移學習,實作地圖要素匹配。套用於地圖資訊提取的深度學習方法普遍面臨地圖數據集搜集困難、自主構建數據整合本過高的問題,大多使用與地圖符號相似的其他數據集進行訓練,這導致模型泛用性差,難以套用到其他地圖任務中。
近年來,大模型成為深度學習的熱點[26] 。相較於普通深度學習模型,通用大模型參數量更多,能夠處理更為復雜的影像,雖然目前還未套用於地圖領域,不過憑借出色的效能和泛用性,在與地圖相似的遙感領域已有所建樹[27] 。其中參數量達到千萬的JointSAREO模型[28] 和參數量上億的Scale-MAE模型[29] 使得遙感視覺任務的精度越來越高,不過相對應的所需軟硬體條件也越來越嚴苛。為降低大模型的使用門檻,Meta公司建立了Segment Anything計畫[30] 。使用超大規模數據集訓練的通用大模型SAM(segment anything model)不僅可以處理多種型別的圖片,還能夠借助提示在小樣本情況下準確地進行影像分割,目前在醫學與遙感影像上均取得很好的效果[31] 。
綜上所述,為了建立一種針對歷史地圖的資訊提取方法,同時避免樣本的高制作成本並且提高泛用性,本文提出將傳統地圖資訊提取方法與深度學習大模型相結合的思路。首先,改良傳統演算法構建小樣本數據集;然後,引入通用大模型SAM,根據數據集特點改進模型結構並進行遷移學習;最後,利用改進的SAM模型實作歷史地圖水系資訊的智慧化提取。相比單一方法,本文思路降低了數據集的構建成本,減少數據集構建中的人為誤差,保證了數據標簽的精度。套用到地圖資訊提取領域的通用大模型SAM既支持小樣本學習,又具有較強的影像特征表達能力,很適合處理復雜地圖數據。SAM的引入能夠驗證當前備受關註的大模型在地圖領域的可用性,為地圖資訊提取提供一種思路。
1 歷史地圖水系資訊提取
本文主要流程如圖1所示。以歷史地圖【寧夏省境黃河沿岸溝渠水道地形圖】為試驗數據,首先,在歷史地圖上裁剪出作為數據集的原影像,在考慮水系符號句法的基礎上,運用模糊C均值聚類(fuzzy C-means,FCM)對原影像進行顏色聚類,並借助改良摺積核的數學形態學方法最佳化聚類結果,構建數據集;然後,針對水系符號數據集特點改進編碼器結構與損失函式,以數據標簽為提示進行遷移學習,更新權重得到改進SAM;最後,只需在地圖上給定提示便可利用改進SAM提取水系資訊。
圖1
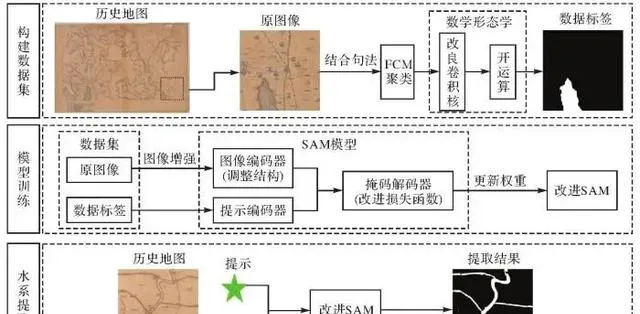
圖1 歷史地圖水系提取流程
Fig. 1 Flowchart of hydrological information extraction from historical maps
1.1 結合符號句法的模糊C均值聚類
模糊C均值聚類是一種基於特征向量劃分的無監督聚類演算法,能夠有效提取目標符號,適用於數據標簽的制作。其主要思想是透過最佳化目標函式得到每個樣本點對所有類中心的隸屬度,並根據隸屬度決定樣本點的類屬,從而實作數據分類。
FCM透過最小化目標函式 J (式(1))與其約束條件(式(2))來實作聚類

(1)
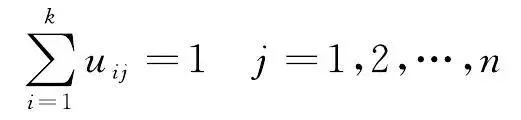
(2)
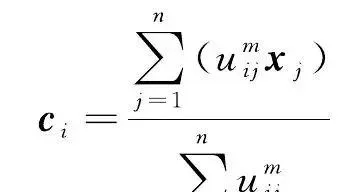
(3)
式中, u ij 表示樣本點 x j 對於類 i 的隸屬度; k 是類別數; n 為樣本個數; m 是一個模糊系數,用來表示樣本屬於某類的重要程度; c i 表示聚類中心。目標函式 J 由相應樣本的隸屬度與該樣本到各類中心的距離的乘積組成,約束條件則限定每個樣本對各個類的隸屬度之和為1。
聚類開始前需要確定模糊系數 m 和類別數 k 。模糊系數 m 一般按經驗取[1.5,2.5][32] ,類別數 k 與地圖符號句法的語音維有關。符號的句法結構可以抽象成語音、語意和句法3個維度[4,33] ,其中語音維包括符號形狀、尺寸、色彩等6個要素。歷史地圖會出現地圖折痕磨損符號,褪色改變符號顏色,地圖印章與底圖混合等情況,因此需要劃分更多類別。在綜合考慮語音維與各類情況後,選定類別數為12,分別是地圖底色、折痕、地圖印章、文字註記、水系(湖泊河流水渠)、褪色水系、河堤、等高線、褪色等高線、公路鐵路、居民地和其他類。前11類出現頻繁、尺寸較大,其中水系包括水系類和褪色水系類,其他類則是孤立點的總和。
確定 m 和 k 後,在滿足約束條件的情況下隨機初始化隸屬度矩陣 u ,根據已知數據更新聚類中心 c i 和隸屬度矩陣 u ,並判斷 J 是否收斂。若收斂則方法結束,不收斂則重復更新 c i 和 u 直到目標函式 J 收斂或者達到最大叠代次數。令 m 分別取1.5、2、2.5進行多次試驗,試驗結果只保留水系。最終發現 m 取2時提取效果最佳(圖2)。
圖2

圖2 FCM聚類結果
Fig. 2 Results of FCM clustering
由於歷史地圖精度有限且褪色嚴重,FCM演算法雖能得到大致結果,但是斷點多,邊界不清晰,受顏色相似的非水系資訊影響大,存在大量噪點與錯誤像素點,無法作為數據標簽使用,需要借助其他方法做進一步最佳化。
1.2 改良摺積核的數學形態學方法
為進一步最佳化聚類得到的結果,需要使用數學形態學方法[34-35] 。數學形態學包含膨脹、腐蝕等多種方法,能夠改變物體形狀,連線斷點並去除孤立點,適用於數據標簽的最佳化。
在進行膨脹腐蝕操作時,首先,定義具有錨點的摺積核,錨點一般為摺積核的中心點;然後,將摺積核與目標影像進行摺積,計算摺積核覆蓋區域的像素點的最大值或最小值,並將該值賦給錨點所在的像素。具體公式為
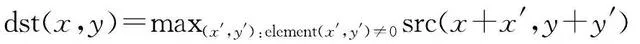
(4)
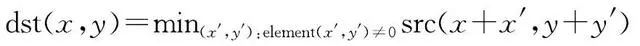
(5)
式中,( x , y )是影像的像素點座標;( x ′, y ′)是摺積核中的座標;max表示求最大值;min表示求最小值;dst為更改後的像素值;src為原始的像素值;element表示座標( x ′, y ′)的像素值。在( x ′, y ′)≠0的前提下,取摺積核中的極值進行像素替換,以此類推直到摺積核遍歷完成整張影像,最終完成膨脹腐蝕操作。
在實際處理影像時,經常會將膨脹腐蝕操作混合使用,稱之為開運算和閉運算。普通開運算是使用值為1的摺積核先腐蝕後膨脹,主要用於消除影像噪點。不過在實際套用中開運算常因無法準確判斷噪點的孤立程度而錯誤消除像素點。本文為提升開運算消除噪點的能力,將值為1的傳統摺積核改良為均值濾波摺積核。均值濾波摺積核的值為摺積核元素個數的倒數,能夠使每個輸出像素為其周圍像素的均值。相比傳統摺積核,均值濾波摺積核可以透過平滑處理影像更好地孤立出噪點,提高消除精度。
為確定最優參數,進行多組試驗。首先將聚類結果二值化來提高影像品質。觀察聚類結果發現斷點大多為2~5個像素,因此摺積核大小分別設定為3×3、5×5,開運算叠代次數分別設為10、20、30,進行6次試驗取最優結果,最終確定摺積核大小為3×3,叠代次數為20次。圖3表示普通開運算和改良開運算的結果對比。可以看出使用均值濾波摺積核的改良開運算提取結果更加準確連貫,噪點和多余像素點都被去除,能夠作為數據標簽使用。
圖3
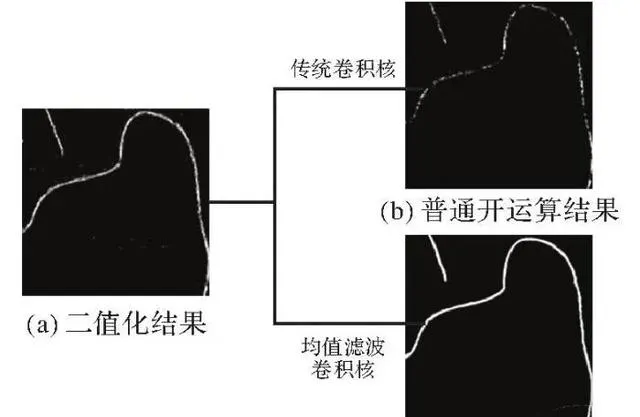
圖3 開運算結果對比
Fig. 3 Comparison of open operation results
1.3 針對水系符號數據集的改進SAM
SAM設計的成功取決於3大要素:可提示的分割、龐大的數據集和出色的模型架構[30] 。可提示的分割使得模型能夠在不改變模型權重的基礎上,透過輸入相關提示詞來獲取想要的輸出結果。龐大的數據集則是借助數據引擎生成的迄今為止最大的標記分割數據集。本文重點關註模型架構。
SAM分為影像編碼器(image encoder)、提示編碼器(prompt encoder)和掩碼解碼器(mask decoder)3部份。影像編碼器使用了掩碼自編碼器(masked autoencoders,MAE)方法預訓練的VIT(vision Transformer)模型[36] 。MAE是一種自監督學習方法,能夠將輸入的圖片分塊,並隨機進行遮蓋,之後借助編碼器和解碼器重構這些被遮蓋的像素。VIT模型是Transformer模型在CV領域的套用[37] ,用於把影像對映到特征空間,具體結構如圖4所示。將圖片輸入影像編碼器後,首先使用摺積分塊縮小尺寸,之後借助Flatten函式將分塊的影像轉換成向量,並與位置資訊(position embedding)相加,相加結果經過Transformer Encoder處理生成特征圖,最後再透過兩層摺積對特征圖進行降維,得到影像嵌入(image embedding)。位置資訊是初始為0的參數矩陣,用於後續位置更新。SAM預設的輸入尺寸為1024×1024像素,本文試驗數據集影像為512×512像素,若直接輸入預設影像編碼器後會存在大量無意義的填充,為提高模型效率將Transformer Encoder調整為8個Transformer Block,其中6個套用局部註意力機制,剩余2個為全域註意力機制。內部的Transformer Block由一個註意力機制模組和多個全連線層組成。
圖4
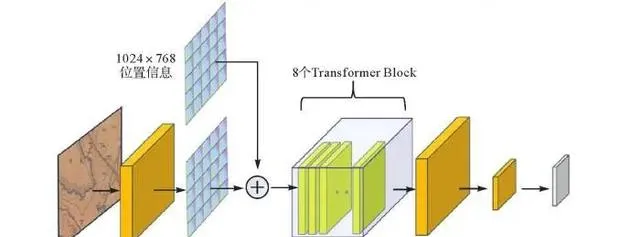
圖4 影像編碼器結構
Fig. 4 Structure of image encoder
提示編碼器的作用是將提示對映到特征空間中,具體結構如圖5所示。其內部包含兩類提示:稀疏提示(點、框、文本)和密集提示(掩碼)。本文輸入的掩碼為密集提示,使用摺積處理,在輸入提示編碼器前首先使用下采樣縮小尺寸,之後經過3層摺積使提示嵌入(prompt embedding)與影像嵌入的尺寸相同。
圖5
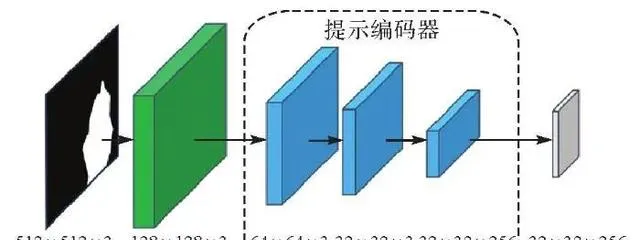
圖5 提示編碼器結構
Fig. 5 Structure of prompt encoder
編碼器得到提示嵌入和影像嵌入,最終逐元素求和並輸入掩碼解碼器中。掩碼解碼器由多個反摺積層和上采樣層組成,用於將影像嵌入、提示嵌入和輸出標記對映到掩碼,基於掩碼更新模型權重,最終生成原始影像大小的分割結果。輸出標記為參數矩陣,用於後續預測分類。反摺積層包括反摺積核、啟用函式和批歸一化等操作,用於對嵌入與特征圖進行特征融合。上采樣層用於恢復影像大小。在更新權重時,掩碼解碼器會根據損失函式的值輸出3個掩碼,由於遷移學習過程中已有明確的數據標簽作為掩碼,因此需要更改結構使其只輸出1個掩碼,提高權重最佳化效率。
水系要素在地圖中占比很小,非水系要素占據大量地圖空間,因此本文構建的水系符號數據集存在正負樣本數量不平衡的問題。大量非水系要素會增加訓練時間,影響模型效果。為解決這一問題本文選擇Focal Loss(FL)損失函式。Focal Loss基於二分類交叉熵損失函式做出改進,是一個能夠動態縮放的交叉熵損失函式,公式為
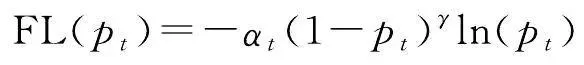
(6)
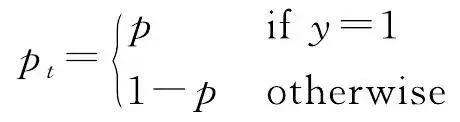
(7)
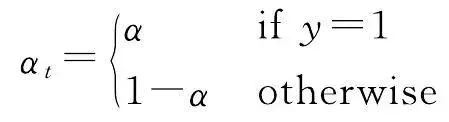
(8)
式中,(1- p t ) γ 為調變因子, γ 的取值範圍為[0,5], p t 和 α t 與 y 的取值相關(見式(7)、式(8)); y 的取值為1和-1,分別代表前景和背景; p 的取值範圍為[0,1],是模型預測屬於前景的機率; α 是權重因子,取值範圍為[0,1]。
Focal Loss透過 α t 抑制正負樣本的數量失衡,透過 γ 抑制難、易樣本的數量失衡。經試驗證明 α 取[0.5,1]能夠增大正樣本權重, γ 取[1,5]能夠增大難樣本的權重,當 γ 增大時減小 α 才能夠取得更好的效果[38] 。因此本文設定兩組超參數,第1組 α =0.5, γ =0.5;第2組 α =0.25, γ =2,其他參數均一致,分別進行遷移學習,訓練過程中損失函式的變化趨勢如圖6所示。
圖6
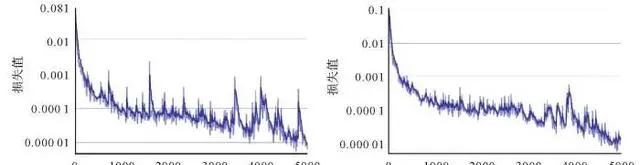
圖6 不同超參數的損失函式曲線
Fig. 6 Loss function curves of different hyperparameters
第1組超參數在第1200個iter(1個iter是網路跑完一次batchsize數量的樣本)得到最佳權重,第2組超參數在第2800個iter得到最佳權重。隨著叠代的進行,第1組超參數出現震蕩現象,而第2組超參數的收斂過程更加平穩,因此,選擇第2組超參數 α =0.25, γ =2。
2 試驗與分析
2.1 試驗環境與數據
試驗在Windows環境下進行,使用Pytorch深度學習框架,程式語言為Python,硬體條件CPU為AMD Ryzen 7 7745HX 16 GB記憶體,GPU為NVIDIA GeForce RTX 4060 8 GB視訊記憶體。本文試驗數據來源於1933—1935年間繪制的【寧夏省境黃河沿岸溝渠水道地形圖】。該圖以地形圖形式詳細記錄了當時寧夏黃河沿岸的地理情況,包含河流、湖泊、道路、溝渠、房屋等各類地理要素。本文研究主要關註水系要素。
試驗歷史地圖中河流溝渠與現代地圖類似,均采用線狀符號表示;湖泊則不同於現代地圖中的藍色面狀符號,水域範圍內采用等高線詳細表示內部地形變化(圖7)。
圖7
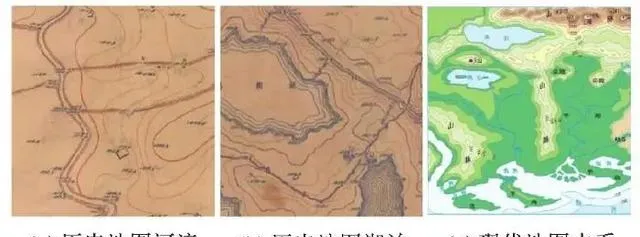
圖7 歷史與現代地圖水系對比
Fig. 7 The comparison of hydrological representation between historical maps and modern maps
水系提取的本質是二分類語意分割,因此在構建數據集時應考慮地圖符號的語意維。語意維強調符號的語意資訊與組成關系,下面結合例項進行分析。
根據符號的語意表達,水系類要素可以進一步劃分為河流、溝渠與湖泊。河流由兩條平行的藍色細線組成,外側用紅色的虛線表示河堤;溝渠為單條藍色細線,外側也為紅色虛線河堤。二者在地圖中都呈線狀且不具備高程資訊,根據語意其標簽形式應為表示河流或溝渠輪廓的線條。湖泊統一用藍色等高線表示,等高線的疏密能夠反映湖泊深度。淺湖內部的等高線細而密集,且集中在湖泊邊緣;隨著湖泊深度變大,等高線會逐漸向湖泊內部延伸,最終布滿整個湖泊。不同深度的湖泊組成關系不同,表示的語意也不同,如果統一用面狀符號表示,既破壞了符號的語意與組成關系,又影響訓練品質和預測精度,同時也無法體現歷史地圖水系符號與現代地形圖的差異。因此在參考語意維後,將湖泊的標簽形式分為等高線未布滿湖泊的環狀符號與等高線布滿湖泊的面狀符號,分別對應現實中的淺水湖和深水湖。
非水系類要素在聚類時已根據語音維初步劃分,接下來結合語意維再進行分析。考慮到地圖底色、折痕和各類褪色現象不具備地圖語意資訊,將非水系整理為地圖印章、文字註記、等高線、道路和居民地5類並依次做好標簽。具體標簽分類如圖8所示。
圖8
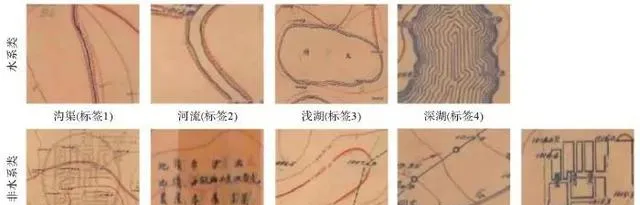
圖8 標簽分類
Fig. 8 Tag classification
運用模糊C均值聚類和改良的數學形態學方法得到水系的數據標簽,借助水平映像、高斯模糊等數據增強操作增加樣本多樣性,最終完成數據集構建。數據集共有210張512×512像素的地圖影像及對應的標簽,單張影像可以對應多種標簽類別,不同類別標簽數量情況見表1,部份樣本影像如圖9所示。其中白色表示水系資訊,黑色為非水系資訊。為驗證本文模型有效性,選取語意分割常用網路U-Net、原始SAM目標分割模型和本文改進的SAM目標分割模型進行多模型對比試驗。
表1 不同類別標簽數量情況
Tab. 1 Number of tags in different categories
| 標簽類別 | 數量 | 占比/(%) |
|---|---|---|
| 溝渠 | 186 | 88.57 |
| 河流 | 59 | 28.10 |
| 淺湖 | 151 | 71.90 |
| 深湖 | 33 | 15.71 |
| 地圖印章 | 15 | 7.14 |
| 文字註記 | 210 | 100.00 |
| 等高線 | 210 | 100.00 |
| 道路 | 91 | 43.30 |
| 居民地 | 118 | 56.19 |
新視窗開啟| 下載CSV
圖9
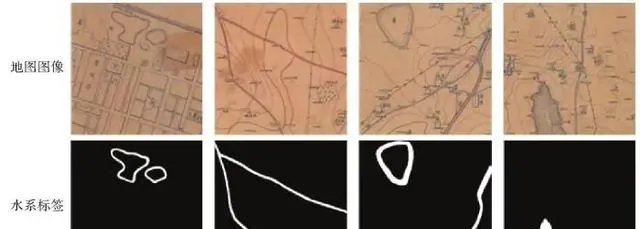
圖9 數據集範例
Fig. 9 Dataset example
2.2 評價指標
本文從像素精度評價水系提取效果,評價指標采用語意分割問題中常見的準確率(accuracy, A )、交並比(IoU)、精度(precision, P )和 F 1 值。準確率表示網路的預測結果的整體準確性,即預測正確的像素個數占總像素個數的比例;交並比是像素的真實值與預測值的交集與聯集的比值;精度是預測正確的像素個數與預測為正類的像素個數的比值; F 1 值是查準率與查全率的平衡。上述各評價指標的具體公式為
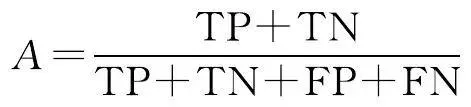
(9)
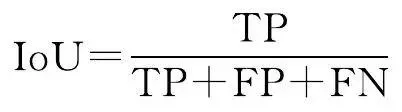
(10)
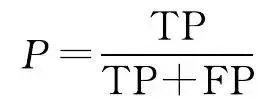
(11)
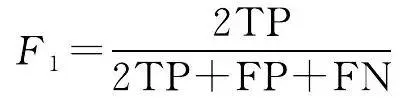
(12)
式中,TP為水系符號被正確預測的像質數量;TN為非水系符號被正確預測的像質數量;FP為非水系符號被預測為水系的像質數量;FN為水系符號被預測為非水系的像質數量。
2.3 試驗結果
預測前,首先基於上文構建的水系符號數據集進行模型訓練。U-Net網路采用監督訓練方法,由於樣本數量較少,采用批次梯度下降演算法,初始學習率為0.000 1,最低學習率為0.000 001,batchsize為8,共訓練200個epoch;改進SAM在預訓練模型參數的基礎上進行遷移學習[39] ,損失函式的超參數設定為 α =0.25, γ =2。原始SAM使用預訓練模型進行預測。最終試驗結果從視覺化和定量研究兩方面來對比,視覺化結果如圖10所示。根據不同的水系類別和幹擾因素具體分析每個模型的提取效果。
圖10

圖10 多模型水系提取效果視覺化對比
Fig. 10 Visual comparison of multi-model hydrological information extraction effects
(1)針對河流溝渠。U-Net雖然能夠得到河流溝渠的大致輪廓,但是不能與地圖中的其他線性符號形成有效區分,並且提取結果寬度變粗,效果較差;原始SAM能夠提取河流溝渠輪廓,但結果不連貫,存在斷點和突出點;改進SAM的提取結果整體連貫性最佳,幾乎沒有斷點與突出點。
(2)針對淺水湖。由於淺水湖的標簽形式為環狀符號,因此U-Net的提取結果依舊存在輪廓加粗、錯誤提取非水系符號的問題;原始SAM提取出湖泊大致輪廓,不足之處在於湖泊邊界部份存在變細和缺失的問題;改進SAM效果最佳,但也存在提取結果與標簽相比更細的問題。
(3)針對深水湖。U-Net可以較好地提取出面積較大的湖泊,不過在湖泊邊緣處精度較低,對於面積較小的湖泊只提取到湖泊邊界;原始SAM提取效果一般,在湖泊邊界處錯誤較多,存在多提錯提的問題;改進SAM與標簽最為相似,不過在湖泊內部存在提取遺漏。
(4)針對受其他因素幹擾的水系。地圖符號用於描述環境要素,具有特定的空間性特征,更易受其他因素的幹擾。例如,河流溝渠與顏色相似的居民地位置很近;湖泊受地形影響與外側的等高線形狀類似;顯示高程與湖泊名稱的文字註記會直接和水系符號重合等。對於這類水系,U-Net的提取效果極差,完全無法進行區分;原始SAM能夠區分水系、等高線和居民地,不過無法處理顏色相似的文字註記;改進SAM除少部份位置重疊的文字註記無法處理外,能夠區分絕大多數幹擾因素與水系符號。
總體來說,U-Net由於訓練數據集規模小,樣本數量不足,使得模型對於地圖抽象特征的表達能力不足,無法區分水系與其他符號,提取結果中除水系符號外還包含等高線、房屋、道路等幹擾符號,整體與標簽差異最大,提取效果最差。原始SAM在提取線狀水系符號時提取效果較好,但針對面狀湖泊時,受顏色和文字註記等因素的影響較大,難以提取出較高精度的湖泊資訊;改進SAM模型透過遷移學習最佳化參數,提取效果最好,提取結果邊界清晰,輪廓連貫,受其他地圖符號幹擾最小,錯提少提現象少。透過結果視覺化和計算模型精度的各項評價指標(表2)對比,驗證了本模型的有效性。
表2 多模型水系提取精度對比
Tab. 2 Comparison of multi-model water system extraction accuracy
| 模型 | 準確率 | IoU | 精度 | F 1 值 |
|---|---|---|---|---|
| U-Net | 84.31 | 61.62 | 62.32 | 76.48 |
| 原始SAM | 89.68 | 76.65 | 84.70 | 84.40 |
| 改進SAM | 94.13 | 83.25 | 91.18 | 90.86 |
新視窗開啟| 下載CSV
由表2可知,本文的改進SAM模型在水系提取方面準確率最高,達到94.13%,比原始SAM要高出4.45%,比U-Net高出18.81%;在其他評價指標方面,改進SAM依然為最高,IoU、精度、 F 1 值分別為83.25%,91.18%、90.86%,比原始SAM高出6.6%、6.48%、6.46%,比U-Net高出28.26%、26.14%、24.58%。透過定量結果對比,證明了本文的模型可以高精度提取歷史地圖水系資訊,相比傳統深度學習方法有很大的進步。
綜上所述,本方法能夠區分並處理歷史地圖中各類復雜資訊,標準化、自動化的提取流程可以用於提取其他型別地圖資訊,或是套用到其他類別地圖中,具有泛用性。
2.4 討論
上述結果證明,本文提出的智慧化歷史地圖水系資訊提取方法十分有效,提取效果優於傳統語意分割網路U-Net和原始SAM,這與SAM在水系符號數據集上的遷移學習是分不開的。
U-Net作為常用的語意分割網路,大部份情況下處理物件為高精度影像或遙感影像,對物體的大小、顏色、位置、方向等具體特征會更敏感,適合處理具有較低語意資訊的醫療影像等。歷史地圖本身精度較低,同時還具有地圖符號特有的句法資訊與符號間邏輯關系[3-4] 。例如等高線作為不同海拔高度的水平面與實際地面的交線,其大多是閉合且互相平行的;由於地勢關系使得河流與等高線的切線近似垂直;由於坡度關系交通運輸路線和人工水渠大多與等高線平行;房屋村落等人類聚集地大多位於等高線稀疏的地方等。上述這些抽象特征使得普通深度學習網路無法很好地理解水系符號與其他地圖符號間的差異,進而導致在水系提取中受其他符號影響大,無法分辨河流、水渠、道路與等高線。SAM通用大模型的大規模預訓練數據集使得模型具有分割不同復雜度影像的能力,因此原始SAM的水系提取效果尚可。不過其設計初衷是通用性和使用廣度,模型結構也是為泛用性服務,這就使得SAM在具體分割任務中仍具有較大的提升空間。結合符號句法構建水系符號數據集,並根據數據集特點改進模型進行遷移學習後,改進SAM可以更好地理解歷史地圖符號,最終提取效果更佳。
研究同時發現,改進SAM的結果與標簽仍存在一定差異,主要表現在3個方面:①會被顏色相近的非水系符號影響,具體體現在提取結果將文字與河流混淆,出現斷點或是突出點,整體比標簽更細或更粗。②在湖泊內部存在提取遺漏,無法精準地提取湖泊面狀符號。③當水系符號間距離過近時,會出現無法準確區分不同水系的問題。發生上述問題的主要原因是歷史地圖精度過低,模糊了文字或是其他符號,使其與河流差異過小;褪色嚴重使得湖泊內部與地圖底色混合,最終導致模型無法區分水系與其他符號。這些不足需要後續的研究進行改進。
將歷史水系提取結果與1979年和2022年的水系遙感影像作對比(圖11),結果顯示80多年來各類水系發生了巨大的變化。河流水渠除唐徠渠、新開渠等歷史名渠外,大多發生改道或偏移,部份溝渠因地勢平坦、有施工基礎變成了交通道路。湖泊面積變小,大部份區域變成濕地,土地肥沃處變為田地,平坦處變為城市建設用地。透過古今水系形態對比能夠清楚地了解黃河沿岸各類水系時空演變格局,為今後的水資源規劃與治理提供參考。
圖11
圖11 水系提取結果與近現代水系遙感影像對比
Fig. 11 Comparison of hydrological information extraction results with modern remote sensing images
3 結論
針對歷史地圖資訊難以有效被利用的問題,本文將傳統演算法與通用大模型SAM相結合,借助模糊C均值聚類和改良的數學形態學方法自動構建數據集,根據數據集特點改進SAM結構與損失函式並進行遷移學習,最終實作了高精度提取歷史地圖水系資訊。試驗結果證明,本文方法相比其他方法具有更高的提取精度,通用大模型SAM的引入驗證了大模型在地圖領域的可用性,為未來地圖資訊提取提供一種思路。得益於改良演算法的高精度和大模型優秀的泛用性,本文方法還能夠套用到現代地形圖或是其他型別地圖資訊提取任務中。
後續工作將在以下幾個方面展開:①對歷史影像做超分辨率處理,提高影像精度,修復褪色以增大各類特征差異。②將本文方法套用到房屋、文字註記、河流道路等其他型別的地圖符號,更全面地檢驗方法的泛用性,尋找不足。③針對不同任務構建專門的地圖符號數據集,提高數據集規模,增大樣本數量。④最佳化模型參數與網路結構,降低執行時間,提高提取精度。
初審:侯 琳
復審:宋啟凡
終審:金 君
資訊
○
○
○
○











