最近很多手機廠商在宣傳AI 手機的概念, 那麽AI 手機怎麽來測量呢? 到底哪家的AI手機最強大? 現在來看似乎並沒有統一的測量標準,剛好我最近在研究手機執行大模型的時候,發現騰訊公司開源的NCNN框架, 這是一個高品質的專門針對行動平台的開源的神經網路推理框架; 進一步研究還發現, 這個NCNN 框架還有一個基準框架benchnn, 這個基準測試,很適合用來測量手機的效能, 尤其是針對當前火熱的AI 手機的概念, 完全可以用這個NCNN的基準測試結果來衡量。
因此記錄下來ncnn的基準測試執行方法, 並以驍龍8 第三代處理器為物件,在紅米手機K70 Pro 上完成測試。

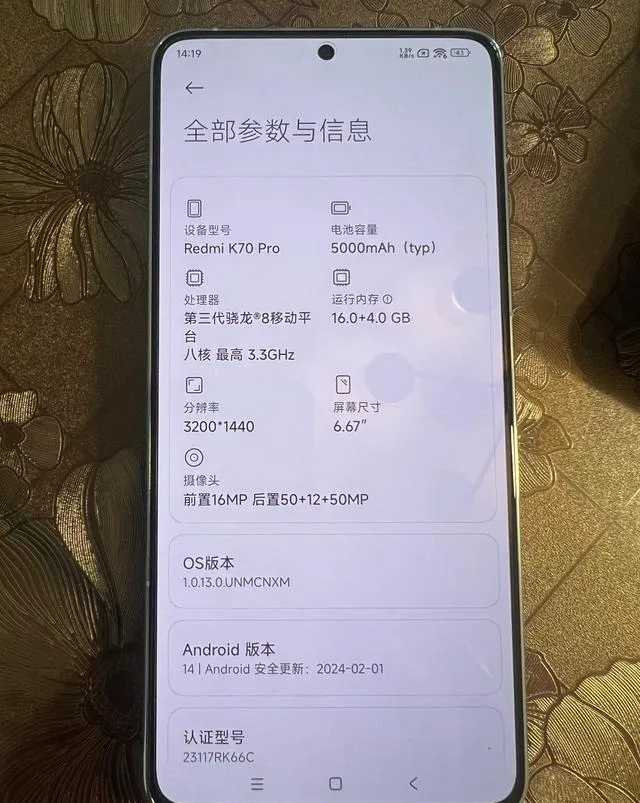

下面請看詳細的評測方法和結果。
首先, 來了解(回顧)一下騰訊的這個ncnn框架。
一、什麽是ncnn

ncnn
ncnn是騰訊優圖實驗室開源的、專門針對行動平台最佳化的高效能神經網路推理框架,計畫地址 github.com/Tencent/ncnn。
這裏是騰訊的官方介紹:
ncnn 是一個為手機端極致最佳化的高效能神經網路前向計算框架。 ncnn 從設計之初深刻考慮手機端的部署和使用。 無第三方依賴,跨平台,手機端 cpu 的速度快於目前所有已知的開源框架。 基於 ncnn,開發者能夠將深度學習演算法輕松移植到手機端高效執行, 開發出人工智慧 APP,將 AI 帶到你的指尖。 ncnn 目前已在騰訊多款套用中使用,如:QQ,Qzone,微信,天天 P 圖等。
功能方面, ncnn也是非常強大,這裏的功能點很多,簡單羅列:
功能概述
支持摺積神經網路,支持多輸入和多分支結構,可計算部份分支
無任何第三方庫依賴,不依賴 BLAS/NNPACK 等計算框架
純 C++ 實作,跨平台,支持 Android / iOS 等
ARM Neon 組譯級良心最佳化,計算速度極快
精細的記憶體管理和數據結構設計,記憶體占用極低
支持多核平行計算加速,ARM big.LITTLE CPU 排程最佳化
支持基於全新低消耗的 Vulkan API GPU 加速
可延伸的模型設計,支持 8bit 量化 和半精度浮點儲存,可匯入 caffe/pytorch/mxnet/onnx/darknet/keras/tensorflow(mlir) 模型
支持直接記憶體零拷貝參照載入網路模型
可註冊自訂層實作並擴充套件
當然,這是一個供app使用的底層框架, 一般人在使用app的時候是感知不到這個框架存在的,但是對於開發者而言,借助於NCNN框架,可以很方便的開發具備AI 功能的App, 下面是一些借助於ncnn的計畫列表,大家可以參考看看有沒有自己能用到的計畫
GitHub - EdVince/ClothingTransfer-NCNN: CT-Net, OpenPose, LIP_JPPNet, DensePose running with ncnn⚡服裝遷移/虛擬試穿⚡ClothingTransfer/Virtual-Try-On⚡: 基於ncnn實作的服裝遷移、虛擬試穿計畫, 可以讓模特試穿不同的服裝,
目標檢測類:
這些app就很多了, 基本的架構就是yolox/opencv+ncnn, 目標檢測演算法使用yolo, 在安卓手機上執行的時候就借助於NCNN, 這裏的計畫特別多,截圖如下:

可以看到有目標檢測,即時物體檢測,人臉檢測,人手檢測,即時疲勞駕駛檢測,口罩檢測,居然還有瞳孔定位,有興趣的同學可以到這個網址進一步檢視 https://github.com/zchrissirhcz/awesome-ncnn

超級分辨率類:
借助於ncnn框架實作對圖片/視訊的分辨率提升,

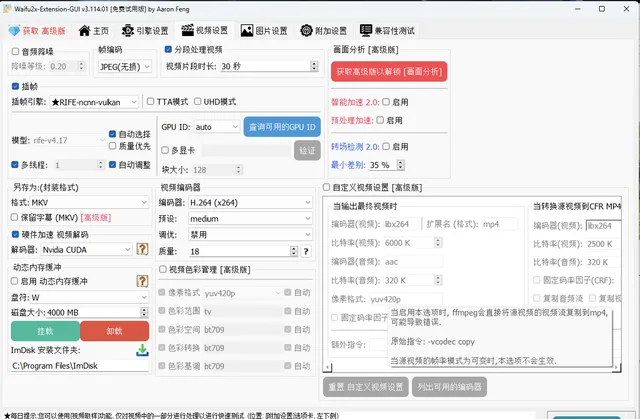
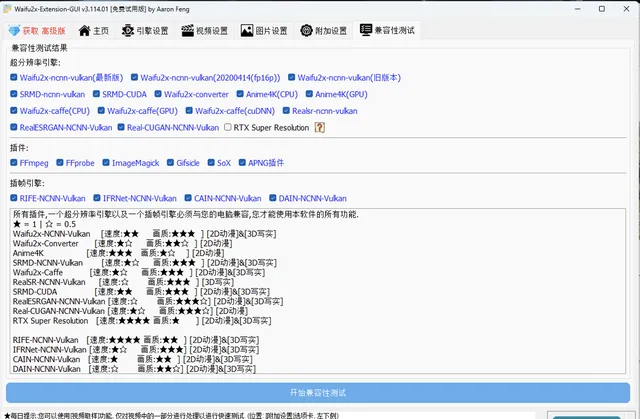
這裏重點推薦Waifu2x-Extension-GUI 這個計畫, 這個計畫可以實作對視訊、影像和 GIF 放大/放大(超分辨率)和視訊幀插值。透過 Waifu2x、Real-ESRGAN、Real-CUGAN、RTX 視訊超分辨率 VSR、SRMD、RealSR、Anime4K、RIFE、IFRNet、CAIN、DAIN 和 ACNet 實作。
界面很樸素, 但是功能很強大:
主頁界面
像素提升(upscale):


圖片放大:

居然還有gif 格式的放大:
還有視訊的放大:
原始視訊(360P):
放大視訊(1440P):
怎麽樣,有沒有興趣試用一下這個工具? 國產軟體,值得推薦啊!
二、為什麽選用NCNN 基準測試benchnn來測量AI 手機?
前面講了很多ncnn的例子,目的是介紹ncnn的強大和套用的廣泛性, 實際上作為2017年國內最先開源的神經網路推理框架, ncnn確實是有很多計畫在使用,那麽為什麽就選用ncnn作為測驗AI 手機的標準呢? 其實主要還是ncnn 這個框架自身的特性,

先來看看騰訊的文件:
功能概述
支持摺積神經網路,支持多輸入和多分支結構,可計算部份分支
無任何第三方庫依賴,不依賴 BLAS/NNPACK 等計算框架
純 C++ 實作,跨平台,支持 Android / iOS 等
ARM Neon 組譯級良心最佳化,計算速度極快
精細的記憶體管理和數據結構設計,記憶體占用極低
支持多核平行計算加速,ARM big.LITTLE CPU 排程最佳化
支持基於全新低消耗的 Vulkan API GPU 加速
可延伸的模型設計,支持 8bit 量化 和半精度浮點儲存,可匯入 caffe/pytorch/mxnet/onnx/darknet/keras/tensorflow(mlir) 模型
支持直接記憶體零拷貝參照載入網路模型
可註冊自訂層實作並擴充套件
從這上面的介紹我們可以看到, ncnn框架整體上沒有第三方的依賴,非常的純凈, 而且對於記憶體管理、ARM Neon 架構有著非常極致的最佳化, 這一點國外的開發人員也比較羨慕~~~
另外一點是,ncnn的相容性非常之好, 幾乎支持所有的平台:
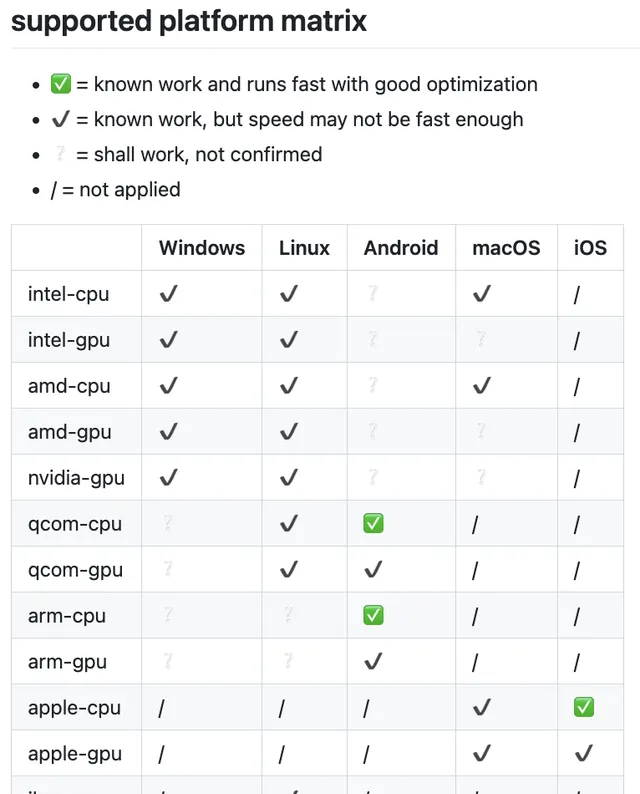
比較具體的支持列表, 華為的鴻蒙OS 赫然在列,強!

基於此, 選用ncnn框架來衡量AI 手機的強弱,就很好理解了, 基本上就接受性和廣泛使用程度而言, 目前除了onnx 之外,就只有ncnn了, 這裏我們當然要選用ncnn了(向nihui大佬致敬~~)
三、ncnn 基準測試benchnn語法
關於ncnn的在地化編譯, 我是在安卓系統上編譯的,具體的方法是透過termux 的linux 模擬環境裏面, 編譯ncnn框架, 具體的做法參見學點AI知識:安卓手機上編譯執行騰訊的NCNN庫

編譯之後, 就可以使用benchnn 這個工具了, 語法如下:
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn --help
Usage: benchncnn [loop count] [num threads] [powersave] [gpu device] [cooling down] [(key=value)...]
param=model.param
shape=[227,227,3],...

因為我們是想測驗驍龍8 Gen 3這款處理器, 因此先來了解一下這個CPU 的基本資訊。
四、驍龍8 Gen 3 基本資訊

CPU 基本資訊:

CPU Qualcomm® Kryo™ CPU
64-bit Architecture
1 Prime core, up to 3.4 GHz**
Arm Cortex-X4 technology
5 Performance cores, up to 3.2 GHz*
2 Efficiency cores, up to 2.3 GHz*

高通官網的GPU 資訊:
Qualcomm® AI Engine
Qualcomm® Adreno™ GPU
Qualcomm® Kryo™ CPU
Qualcomm® Hexagon™ NPU:
- Fused AI accelerator architecture
- Hexagon scalar, vector, and tensor accelerators
- Hexagon Direct Link
- Upgraded Micro Tile Inferencing
- Upgraded power delivery system
- Support for mix precision (INT8+INT16)
- Support for all precisions (INT4, INT8, INT16, FP16)
GPU 資訊:
adb shell dumpsys SurfaceFlinger | grep GLES
結果:
------------RE GLES------------
GLES: Qualcomm, Adreno (TM) 750, OpenGL ES 3.2 [email protected] (GIT@62c1f322ce, Id0077aad60, 1700555917) (Date:11/21/23)
五、CPU 模式執行benchnn
這是一個例子,使用4個執行緒,8次迴圈(loop), 使用CPU(第四個參數gpu 為-1 ):
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn 8 4 0 -1 1loop_count = 8num_threads = 4powersave = 0gpu_device = -1cooling_down = 1squeezenet min = 2.36 max = 2.50 avg = 2.41squeezenet_int8 min = 1.96 max = 2.06 avg = 2.00mobilenet min = 3.95 max = 8.71 avg = 4.64mobilenet_int8 min = 2.23 max = 2.36 avg = 2.30mobilenet_v2 min = 2.80 max = 2.98 avg = 2.89mobilenet_v3 min = 2.63 max = 2.80 avg = 2.72shufflenet min = 2.00 max = 2.20 avg = 2.10shufflenet_v2 min = 1.81 max = 1.98 avg = 1.87mnasnet min = 2.87 max = 3.04 avg = 2.94proxylessnasnet min = 3.23 max = 3.42 avg = 3.31efficientnet_b0 min = 5.33 max = 5.63 avg = 5.44efficientnetv2_b0 min = 6.27 max = 6.65 avg = 6.42regnety_400m min = 5.70 max = 5.83 avg = 5.79blazeface min = 0.71 max = 1.52 avg = 1.09googlenet min = 9.06 max = 9.45 avg = 9.19googlenet_int8 min = 7.16 max = 7.39 avg = 7.27resnet18 min = 6.64 max = 6.84 avg = 6.74resnet18_int8 min = 4.89 max = 5.07 avg = 4.95alexnet min = 7.51 max = 7.60 avg = 7.56vgg16 min = 36.01 max = 36.30 avg = 36.13vgg16_int8 min = 33.57 max = 34.12 avg = 33.81resnet50 min = 18.57 max = 18.96 avg = 18.75resnet50_int8 min = 10.55 max = 10.81 avg = 10.64squeezenet_ssd min = 7.28 max = 7.68 avg = 7.47squeezenet_ssd_int8 min = 6.14 max = 6.82 avg = 6.43mobilenet_ssd min = 8.54 max = 9.06 avg = 8.66mobilenet_ssd_int8 min = 4.93 max = 5.14 avg = 5.02mobilenet_yolo min = 20.36 max = 22.02 avg = 20.80mobilenetv2_yolov3 min = 11.46 max = 11.61 avg = 11.53yolov4-tiny min = 15.20 max = 15.44 avg = 15.33nanodet_m min = 5.14 max = 5.57 avg = 5.28yolo-fastest-1.1 min = 2.40 max = 2.77 avg = 2.52yolo-fastestv2 min = 2.00 max = 2.28 avg = 2.09vision_transformer min = 243.12 max = 248.61 avg = 244.42FastestDet min = 1.88 max = 2.12 avg = 1.97
既然CPU 有8個核心,那麽就來8個執行緒來跑一跑:
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn 8 8 0 -1 1loop_count = 8num_threads = 8powersave = 0gpu_device = -1cooling_down = 1squeezenet min = 7.35 max = 8.88 avg = 7.65squeezenet_int8 min = 4.28 max = 4.41 avg = 4.32mobilenet min = 6.11 max = 7.43 avg = 6.43mobilenet_int8 min = 4.55 max = 4.75 avg = 4.61mobilenet_v2 min = 5.83 max = 6.54 avg = 6.01mobilenet_v3 min = 4.64 max = 4.96 avg = 4.76shufflenet min = 5.65 max = 7.19 avg = 6.00shufflenet_v2 min = 7.20 max = 9.83 avg = 7.83mnasnet min = 4.94 max = 6.56 avg = 5.33proxylessnasnet min = 6.46 max = 9.66 avg = 7.88efficientnet_b0 min = 9.32 max = 10.82 avg = 9.68efficientnetv2_b0 min = 11.19 max = 14.87 avg = 12.11regnety_400m min = 11.15 max = 11.73 avg = 11.31blazeface min = 2.12 max = 2.65 avg = 2.31googlenet min = 17.73 max = 21.76 avg = 18.90googlenet_int8 min = 12.51 max = 13.63 avg = 12.78resnet18 min = 9.45 max = 28.39 avg = 12.39resnet18_int8 min = 9.21 max = 9.61 avg = 9.41alexnet min = 10.60 max = 12.25 avg = 11.10vgg16 min = 53.30 max = 88.63 avg = 59.98vgg16_int8 min = 59.42 max = 95.09 avg = 66.68resnet50 min = 26.97 max = 29.22 avg = 27.72resnet50_int8 min = 18.51 max = 25.78 avg = 20.98squeezenet_ssd min = 12.53 max = 13.09 avg = 12.75squeezenet_ssd_int8 min = 13.05 max = 15.11 avg = 13.47mobilenet_ssd min = 14.60 max = 26.02 avg = 16.76mobilenet_ssd_int8 min = 8.19 max = 8.52 avg = 8.31mobilenet_yolo min = 36.56 max = 72.06 avg = 43.64mobilenetv2_yolov3 min = 16.56 max = 29.45 avg = 19.33yolov4-tiny min = 20.13 max = 23.69 avg = 22.23nanodet_m min = 10.30 max = 13.62 avg = 11.38yolo-fastest-1.1 min = 4.22 max = 5.33 avg = 4.43yolo-fastestv2 min = 4.71 max = 6.93 avg = 5.28vision_transformer min = 339.24 max = 460.96 avg = 393.47FastestDet min = 4.53 max = 6.98 avg = 5.29
六、GPU 模式來執行benchnn
對於GPU,NCNN使用了Vulkan API, 為了確保Vulkan是否正確配置,先執行一下vulkaninfo 這個基本命令:
root@localhost:~/ncnn/benchmark# vulkaninfo --summaryWARNING: [Loader Message] Code 0 : terminator_CreateInstance: Received return code -3 from call to vkCreateInstance in ICD /usr/lib/aarch64-linux-gnu/libvulkan_virtio.so. Skipping this driver.'DISPLAY' environment variable not set... skipping surface infoerror: XDG_RUNTIME_DIR is invalid or not set in the environment.error: XDG_RUNTIME_DIR is invalid or not set in the environment.error: XDG_RUNTIME_DIR is invalid or not set in the environment.error: XDG_RUNTIME_DIR is invalid or not set in the environment.error: XDG_RUNTIME_DIR is invalid or not set in the environment.error: XDG_RUNTIME_DIR is invalid or not set in the environment.error: XDG_RUNTIME_DIR is invalid or not set in the environment.==========VULKANINFO==========Vulkan Instance Version: 1.3.275Instance Extensions: count = 23-------------------------------VK_EXT_acquire_drm_display : extension revision 1VK_EXT_acquire_xlib_display : extension revision 1VK_EXT_debug_report : extension revision 10VK_EXT_debug_utils : extension revision 2VK_EXT_direct_mode_display : extension revision 1VK_EXT_display_surface_counter : extension revision 1VK_EXT_surface_maintenance1 : extension revision 1VK_EXT_swapchain_colorspace : extension revision 4VK_KHR_device_group_creation : extension revision 1VK_KHR_display : extension revision 23VK_KHR_external_fence_capabilities : extension revision 1VK_KHR_external_memory_capabilities : extension revision 1VK_KHR_external_semaphore_capabilities : extension revision 1VK_KHR_get_display_properties2 : extension revision 1VK_KHR_get_physical_device_properties2 : extension revision 2VK_KHR_get_surface_capabilities2 : extension revision 1VK_KHR_portability_enumeration : extension revision 1VK_KHR_surface : extension revision 25VK_KHR_surface_protected_capabilities : extension revision 1VK_KHR_wayland_surface : extension revision 6VK_KHR_xcb_surface : extension revision 6VK_KHR_xlib_surface : extension revision 6VK_LUNARG_direct_driver_loading : extension revision 1Instance Layers: count = 2--------------------------VK_LAYER_MESA_device_select Linux device selection layer 1.3.211 version 1VK_LAYER_MESA_overlay Mesa Overlay layer 1.3.211 version 1Devices:========GPU0:apiVersion = 1.3.274driverVersion = 0.0.1vendorID = 0x10005deviceID = 0x0000deviceType = PHYSICAL_DEVICE_TYPE_CPUdeviceName = llvmpipe (LLVM 17.0.6, 128 bits)driverID = DRIVER_ID_MESA_LLVMPIPEdriverName = llvmpipedriverInfo = Mesa 24.0.5-1ubuntu1 (LLVM 17.0.6)conformanceVersion = 1.3.1.1deviceUUID = 6d657361-3234-2e30-2e35-xxxxxxxxxxxxdriverUUID = 6c6c766d-7069-7065-5555-xxxxxxxxxxxxroot@localhost:~/ncnn/benchmark#
上面展現的是CPU的推理,現在看看CPU模式下(第四個參數gpu 為0,使用第1個GPU ),benchnn的結果怎麽樣:
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn 8 4 0 0 1loop_count = 8num_threads = 4powersave = 0gpu_device = 0cooling_down = 1squeezenet min = 2.73 max = 2.83 avg = 2.79squeezenet_int8 min = 2.27 max = 2.37 avg = 2.32mobilenet min = 4.56 max = 4.64 avg = 4.60mobilenet_int8 min = 2.61 max = 2.77 avg = 2.67mobilenet_v2 min = 3.26 max = 3.49 avg = 3.38mobilenet_v3 min = 3.02 max = 3.27 avg = 3.14shufflenet min = 2.31 max = 2.61 avg = 2.46shufflenet_v2 min = 2.11 max = 2.29 avg = 2.20mnasnet min = 3.37 max = 3.51 avg = 3.43proxylessnasnet min = 3.73 max = 4.07 avg = 3.88efficientnet_b0 min = 6.17 max = 6.56 avg = 6.30efficientnetv2_b0 min = 7.21 max = 7.49 avg = 7.35regnety_400m min = 6.71 max = 6.97 avg = 6.80blazeface min = 0.82 max = 0.95 avg = 0.86googlenet min = 10.44 max = 10.74 avg = 10.55googlenet_int8 min = 8.25 max = 8.41 avg = 8.32resnet18 min = 7.47 max = 7.69 avg = 7.54resnet18_int8 min = 5.55 max = 5.78 avg = 5.63alexnet min = 8.20 max = 8.41 avg = 8.27vgg16 min = 40.02 max = 40.73 avg = 40.42vgg16_int8 min = 37.65 max = 42.27 avg = 39.12resnet50 min = 21.32 max = 21.54 avg = 21.43resnet50_int8 min = 12.07 max = 12.38 avg = 12.22squeezenet_ssd min = 8.20 max = 8.63 avg = 8.41squeezenet_ssd_int8 min = 6.88 max = 7.73 avg = 7.27mobilenet_ssd min = 9.83 max = 10.27 avg = 9.93mobilenet_ssd_int8 min = 5.69 max = 5.91 avg = 5.75mobilenet_yolo min = 23.73 max = 24.30 avg = 24.01mobilenetv2_yolov3 min = 13.11 max = 13.43 avg = 13.24yolov4-tiny min = 17.56 max = 19.04 avg = 17.80nanodet_m min = 6.12 max = 6.57 avg = 6.28yolo-fastest-1.1 min = 2.76 max = 3.08 avg = 2.86yolo-fastestv2 min = 2.28 max = 2.44 avg = 2.36vision_transformer min = 284.04 max = 290.75 avg = 287.25FastestDet min = 2.21 max = 2.49 avg = 2.31
跑一個8執行緒的GPU推理:
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn 8 8 0 1 1loop_count = 8num_threads = 8powersave = 0gpu_device = 1cooling_down = 1squeezenet min = 4.19 max = 12.36 avg = 7.60squeezenet_int8 min = 5.13 max = 6.05 avg = 5.59mobilenet min = 6.64 max = 6.78 avg = 6.70mobilenet_int8 min = 4.24 max = 7.84 avg = 5.12mobilenet_v2 min = 14.45 max = 17.51 avg = 15.52mobilenet_v3 min = 4.72 max = 4.97 avg = 4.84shufflenet min = 4.27 max = 6.32 avg = 4.75shufflenet_v2 min = 5.09 max = 5.29 avg = 5.16mnasnet min = 4.74 max = 5.07 avg = 4.91proxylessnasnet min = 6.64 max = 7.04 avg = 6.77efficientnet_b0 min = 10.49 max = 12.27 avg = 11.07efficientnetv2_b0 min = 21.73 max = 23.92 avg = 22.20regnety_400m min = 15.11 max = 16.45 avg = 15.46blazeface min = 2.04 max = 3.32 avg = 2.30googlenet min = 15.56 max = 16.37 avg = 15.82googlenet_int8 min = 14.33 max = 15.88 avg = 14.93resnet18 min = 10.93 max = 11.40 avg = 11.15resnet18_int8 min = 9.07 max = 9.56 avg = 9.30alexnet min = 11.36 max = 11.91 avg = 11.54vgg16 min = 65.51 max = 82.50 avg = 69.47vgg16_int8 min = 56.88 max = 61.46 avg = 58.33resnet50 min = 27.11 max = 34.45 avg = 30.53resnet50_int8 min = 18.92 max = 20.28 avg = 19.16squeezenet_ssd min = 12.00 max = 16.68 avg = 13.26squeezenet_ssd_int8 min = 13.03 max = 16.40 avg = 14.04mobilenet_ssd min = 13.31 max = 15.48 avg = 14.03mobilenet_ssd_int8 min = 9.52 max = 12.70 avg = 10.24mobilenet_yolo min = 45.97 max = 105.43 avg = 76.82mobilenetv2_yolov3 min = 18.20 max = 21.84 avg = 20.05yolov4-tiny min = 24.67 max = 33.68 avg = 29.67nanodet_m min = 13.36 max = 14.26 avg = 13.87yolo-fastest-1.1 min = 6.96 max = 7.62 avg = 7.17yolo-fastestv2 min = 4.16 max = 7.57 avg = 4.66vision_transformer min = 380.71 max = 469.66 avg = 419.79FastestDet min = 4.61 max = 4.87 avg = 4.69root@localhost:~/ncnn/benchmark#
執行過程:
七、結論
寫的太長了, 先簡單說一下結論吧, 下一篇再來比較各個芯片之間的強弱:
CPU 模式效能大於 GPU模式
這個其實有點超乎意料, 但是請看第一個CPU模式下執行的結果:
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn 8 4 0 -1 1loop_count = 8num_threads = 4powersave = 0gpu_device = -1cooling_down = 1squeezenet min = 2.36 max = 2.50 avg = 2.41
再來看看GPU模式下的執行結果
root@localhost:~/ncnn/benchmark# ../build/benchmark/benchncnn 8 4 0 0 1loop_count = 8num_threads = 4powersave = 0gpu_device = 0cooling_down = 1squeezenet min = 2.73 max = 2.83 avg = 2.79
CPU 模式下執行squeezenet的平均結果為2.41, 而GPU 模式下的平均結果為2.79, CPU勝 ✌ ️。
至於其他計畫的對比, 也是一樣, 這個其實可以理解, 畢竟驍龍8 Gen 3 有8核CPU, 而 GPU 只有一個, 而且ncnn並沒有特別最佳化高通的這款GPU。
本文主要是對高通驍龍8 Gen3的CPU和GPU 模式下的成績做對比,算是自己和自己比,橫向對比,後續會繼續對高通驍龍8 Gen3的縱向對比, 看看和其他處理器相比怎麽樣。











