編輯:桃子 好困
【新智元導讀】一台4090筆記本,秒生1K品質高畫質圖。輝達聯合MIT清華團隊提出的Sana架構,得益於核心架構創新,具備了驚人的影像生成速度,而且最高能實作4k分辨率。
一台16GB的4090筆記本,僅需0.37秒,直接吐出1024×1024像素圖片。
如此神速AI生圖工具,竟是出自輝達MIT清華全華人團隊之筆!
正如其名字一樣,Sana能以驚人速度合成高分辨率、高品質,且具有強文本-影像對其能力的模型。
而且,它還能高效生成高達4096×4096像素的影像。

計畫主頁:https://nvlabs.github.io/Sana/
論文地址:https://arxiv.org/abs/2410.10629
Sana的核心設計包含了以下幾個要素:
深度壓縮自編碼器(AE): 傳統自編碼器只能將影像壓縮8倍,全新AE可將影像壓縮32倍,有效減少了潛在token的數量。
線性DiT(Diffusion Transformer): 用「線性註意力」替換了DiT中所有的普通註意力,在高分辨率下更加高效,且不會犧牲品質。
基於僅解碼器模型的文本編碼器: 用現代的僅解碼器SLM替換T5作為文本編碼器,並設計了復雜的人類指令,透過上下文學習來增強影像-文本對齊。
高效的訓練和采樣: 提出Flow-DPM-Solver來減少采樣步驟,並透過高效的標題標註和選擇來加速收斂。
基於以上的演算法創新,相較於領先擴散模型Flux-12B,Sana-0.6B不僅參數小12倍,重要的是吞吐量飆升100倍。
以後,低成本的內容創作,Sana才堪稱這一領域的王者。

效果一覽
一只賽博貓,和一個帶有「SANA」字樣的霓虹燈牌。

一位站在山頂上的巫師,在夜空中施展魔法,形成了由彩色能量組成的「NV」字樣。

在人物的生成方面,Sana對小女孩面部的描繪可以說是非常地細致了。

下面來看個更復雜的:
一艘海盜船被困在宇宙漩渦星雲中,透過模擬宇宙海灘旋渦的特效引擎渲染,呈現出令人驚嘆的立體光效。場景中彌漫著壯麗的環境光和光汙染,營造出電影般的氛圍。整幅作品采用新藝術風格,由藝術家SenseiJaye創作的插畫藝術,充滿精致細節。

甚至,像下面這種超級復雜的提示,Sana也能get到其中的關鍵資訊,並生成相應的元素和風格。
Prompt:a stunning and luxurious bedroom carved into a rocky mountainside seamlessly blending nature with modern design with a plush earth-toned bed textured stone walls circular fireplace massive uniquely shaped window framing snow-capped mountains dense forests, tranquil mountain retreat offering breathtaking views of alpine landscape wooden floors soft rugs rustic sophisticated charm, cozy tranquil peaceful relaxing perfect escape unwind connect with nature, soothing intimate elegance modern design raw beauty of nature harmonious blend captivating view enchanting inviting space, soft ambient lighting warm hues indirect lighting natural daylight balanced inviting glow

順便,團隊還給經典梗圖,生成了一個卡通版變體(右)。

設計細節
Sana的核心元件,已在開頭簡要給出介紹。接下來,將更進一步展開它們實作的細節。
模型架構的細節,如下表所示。

- 深度壓縮自編碼器
研究人員引入的全新自編碼器(AE),大幅將縮放因子提高至32倍。
過去,主流的AE將影像的長度和寬度,只能壓縮8倍(AE-F8)。
與AE-F8相比,AE-F32輸出的潛在token數量減少了16倍,這對於高效訓練和生成超高分辨率影像(如4K分辨率)至關重要。

- 高效線性DiT(Diffusion Transformer)
原始DiT的自註意力計算復雜度為O(N²),在處理高分辨率影像時呈二次增長。
線性DiT在此替換了傳統的二次註意力機制,將計算復雜度從O(N²)降低到O(N)。
與此同時,研究人員還提出了Mix-FFN,可以在多層感知器(MLP)中使用3×3深度摺積,增強了token的局部資訊。
實驗結果顯示,線性註意力達到了與傳統註意力相當的結果,在4K影像生成方面將延遲縮短了1.7倍。
此外,Mix-FFN無需位置編碼(NoPE)就能保持生成品質,成為第一個不使用位置嵌入的DiT。
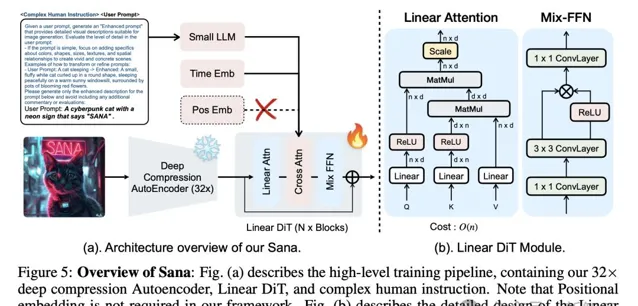
- 基於僅解碼器「小語言模型」的文本編碼器
這裏,研究人員使用了Gemma(僅解碼器LLM)作為文本編碼器,以增強對提示詞的理解和推理能力。
盡管T2I生成模型多年來取得了顯著進展,但大多數現有模型仍依賴CLIP或T5進行文本編碼,這些模型往往缺乏強大的文本理解和指令跟隨能力。
與CLIP或T5不同,Gemma提供了更優的文本理解和指令跟隨能力,由此解訓練了不穩定的問題。
他們還設計了復雜人類指令(CHI),來利用Gemma強大指令跟隨、上下文學習和推理能力,改善了影像-文本對齊。

在速度相近的情況下,Gemma-2B模型比T5-large效能更好,與更大更慢的T5-XXL效能相當。

- 高效訓練和推理策略
另外,研究人員還提出了一套自動標註和訓練策略,以提加文本和影像之間的一致性。
首先,對於每張影像,利用多個視覺語言模型(VLM)生成重新描述。盡管這些VLM的能力各不相同,但它們的互補優勢提高了描述的多樣性。
此外,他們還提出了一種基於clipscore的訓練策略,根據機率動態選擇與影像對應的多個描述中具有高clip分數的描述。
實驗表明,這種方法改善了訓練收斂和文本-影像對齊能力。
此外,與廣泛使用的Flow-Euler-Solver相比,團隊提出的Flow-DPM-Solver將推理采樣步驟從28-50步顯著減少到14-20步,同時還能獲得更優的結果。

整體效能
如下表1中,將Sana與當前最先進的文本生成影像擴散模型進行了比較。
對於512×512分辨率:- Sana-0.6的吞吐量比具有相似模型大小的PixArt-Σ快5倍- 在FID、Clip Score、GenEval和DPG-Bench等方面,Sana-0.6顯著優於PixArt-Σ
對於1024×1024分辨率:- Sana比大多數參數量少於3B的模型效能強得多- 在推理延遲方面表現尤為出色
與最先進的大型模型FLUX-dev的比較:- 在DPG-Bench上,準確率相當- 在GenEval上,效能略低- 然而,Sana-0.6B的吞吐量快39倍,Sana-1.6B快23倍

Sana-0.6吞吐量,要比當前最先進4096x4096影像生成方法Flux,快100倍。

而在1024×1024分辨率下,Sana的吞吐量要快40倍。

如下是,Sana-1.6B與其他模型視覺化效能比較。很顯然,Sana模型生成速度更快,品質更高。

終端裝置部署
為了增強邊緣部署,研究人員使用8位元整數對模型進行量化。
而且,他們還在CUDA C++中實作了W8A8 GEMM內核,並采用內核融合技術來減少不必要的啟用載入和儲存帶來的開銷,從而提高整體效能。
如下表5所示,研究人員在消費級4090上部署最佳化前後模型的結果比較。
在生成1024x1024影像方面,最佳化後模型實作了2.4倍加速,僅用0.37秒就生成了同等高品質影像。

作者介紹
Enze Xie(謝恩澤)

共同一作Enze Xie是NVIDIA Research的高級研究科學家,隸屬於由麻省理工學院的Song Han教授領導的高效AI團隊。此前,曾在華為諾亞方舟實驗室(香港)AI理論實驗室擔任高級研究員和生成式AI研究主管。
他於2022年在香港大學電腦科學系獲得博士學位,導師是Ping Luo教授,聯合導師是Wenping Wang教授。並於朋友Wenhai Wang密切合作。
在攻讀博士學習期間,他與阿德雷德大學的Chunhua Shen教授、加州理工學院的Anima Anandkumar教授以及多倫多大學的Sanja Fidler教授共事。同時,還與Facebook和NVIDIA等業界的多位研究人員進行了合作。
他的研究方向是高效的AIGC/LLM/VLM,並在例項級檢測和自監督/半監督/弱監督學習領域做了一些工作——開發了多個CV領域非常知名的演算法,以及一個2000多星的自監督學習框架OpenSelfSup(現名為mmselfsup)。
- PolarMask(CVPR 2020十大影響力論文排名第十)
- PVT(ICCV 2021十大影響力論文排名第二)
- SegFormer(NeurIPS 2021十大影響力論文排名第三)
- BEVFormer(ECCV 2022十大影響力論文排名第六)
Junsong Chen

共同一作Junsong Chen是NVIDIA Research的研究實習生,由Enze Xie博士和Song Han教授指導。同時,他也是大連理工大學IIAU實驗室的博士生,導師是Huchuan Lu教授。
他的研究領域是生成式AI和機器學習的交叉,特別是深度學習及其套用的演算法與系統協同設計。
此前,他曾在香港大學擔任研究助理,由Ping Luo教授的指導。
Song Han(韓松)

Song Han是MIT電氣工程與電腦科學系的副教授。此前,他在史丹佛大學獲得博士學位。
他提出了包括剪枝和量化在內廣泛用於高效AI計算的「深度壓縮」技術,以及首次將權重稀疏性引入現代AI芯片的「高效推理引擎」——ISCA 50年歷史上參照次數最多的前五篇論文之一。
他開創了TinyML研究,將深度學習引入物聯網裝置,實作邊緣學習。
他的團隊在硬體感知神經架構搜尋方面的工作使使用者能夠設計、最佳化、縮小和部署 AI 模型到資源受限的硬體裝置,在多個AI頂會的低功耗電腦視覺比賽中獲得第一名。
最近,團隊在大語言模型量化/加速(SmoothQuant、AWQ、StreamingLLM)方面的工作,有效提高了LLM推理的效率,並被NVIDIA TensorRT-LLM采用。
Song Han憑借著在「深度壓縮」方面的貢獻獲得了ICLR和FPGA的最佳論文獎,並被MIT Technology Review評選為「35歲以下科技創新35人」。與此同時,他在「加速機器學習的高效演算法和硬體」方面的研究,則獲得了NSF CAREER獎、IEEE「AIs 10 to Watch: The Future of AI」獎和史隆研究獎學金。
他是DeePhi(被AMD收購)的聯合創始人,也是OmniML(被NVIDIA收購)的聯合創始人。
參考資料:
https://nvlabs.github.io/Sana/
https://www.linkedin.com/feed/update/urn:li:activity:7251843706310275072/











