最新一代人工智慧或將開啟新一輪科技革命,全面提升各種人機互動體驗。
人工智慧日益融入人們的日常生活,在方方面面帶來深刻變化。基於人工智慧的文本和影像生成工具可以建立出令人難以置信的內容。不僅如此,人工智慧的觸角已從視覺和文字媒介,伸向語音轉文字(STT)和自然語言處理(NLP)等音訊套用,展現出巨大潛力。然而,音訊套用品質大幅提高是否僅僅歸功於最新一代基於大語言模型的生成式人工智慧?還是說硬體依然功不可沒?就拿高訊雜比(SNR)微機電系統(MEMS)麥克風來說,它為實作這種必將改變人們日常生活的新質人機互動做出了什麽貢獻?本文將探討這些問題並深入分析高訊雜比MEMS麥克風在文字轉語音(TTS)和自然語言處理(NLP)等前沿音訊套用的開發中所起的關鍵作用。

人們每天佩戴耳機的時間越來越長。隨著越來越多的人選擇在咖啡館等公共場所辦公,為了靜享安寧或是參加會議,人們紛紛使用耳機來隔絕外界喧囂。閑暇時,人們也願意戴著耳機打遊戲、聽音樂或有聲讀物或者與朋友交談。由於佩戴時間越來越長,除舒適度之外,音訊品質也成為重要的選購標準。越來越多的人在選購耳機時對「高級音訊功能」感興趣,如空間音訊、清晰語音通話和低延遲等。

圖1:基於高訊雜比MEMS麥克風的語音辨識準確率更高
賦予智慧型手機內建語音助手更大優勢
語音辨識和語音生成是消費電子產品和汽車的重要音訊功能。近幾年來,包括Siri和Alexa在內的語音助手一直在簡化操作並推出新的套用,如透過語音命令控制智慧家居裝置。如今,從智慧型手機(圖1)和耳機到智慧型電視、智慧音箱、智慧家居裝置、膝上型電腦和平板電腦,各式各樣的裝置都配備了整合語音助手。整合在裝置中的語音助手(如智慧型手機、耳機、智慧型電視和智慧音箱)依賴於這些麥克風捕捉到的高品質音訊輸入。高訊雜比(訊號與雜訊比)麥克風在實作卓越音訊品質方面起著關鍵作用;對於遠場套用,如智慧音箱,高訊雜比麥克風可以更好地捕捉音訊;真無線耳機(TWS)中的主動降噪(ANC)和透傳模式等功能也受益於高訊雜比麥克風,提升了使用者體驗。汽車也廣泛使用語音助手來控制多種不同功能,以便駕駛員雙手不離開方向盤即可完成操作。
SAR預測,到2028年,帶整合語音助手的裝置的市場總銷量將增至每年30億台,復合年增長率達5%。¹
人工智慧在音訊領域的套用前景
另外目前的系統還不夠完美。口音、語病或簡單的背景雜訊等仍然會導致語音辨識失敗。語音輸出聽起來也非常生硬,與真人發音有很大差別。
最新一代人工智慧或將開啟新一輪科技革命,全面提升各種人機互動體驗。生成式人工智慧音訊的優勢不僅在於增強語音助手的功能,還在於它能夠更好地理解人類的意圖。例如,人工智慧生成語音與真人發音幾乎難以分辨,從而可以為視障群體提供更好的幫助。各種數位平台都可以利用人工智慧音訊來提升使用者體驗,娛樂行業或客戶支持領域也可以探索人工智慧音訊帶來的新的可能性。
生成式人工智慧音訊的一個重要套用是語音轉文字,即將說的話轉換成文字。使用人工智慧可以提高速度和準確率。語音轉文字(STT)結合文字轉語音(TTS),可以在諸如膝上型電腦或智慧型手機等消費電子產品中實作多種套用,包括整合語音助手以及自動轉錄會議。在會議中,基於人工智慧的套用可以總結出,以把握討論的精神實質。在會議進行過程中,您可以檢視不同人提出的觀點,以確保全面考慮每個人的意見。
自然語言處理(NLP)
和生成富有表現力的語音
自然語言處理(NLP)是生成式人工智慧語音的基礎技術。它致力於理解口頭語言的含義,而不考慮口音、口語化表達、發音含糊不清以及口頭語言與書面語言之間的其他差異。自然語言處理還可以根據語速、語調和語氣,辨識出觀點和情緒。人可以發出各種各樣的聲音,因此,自然語言處理的聲音采集必須盡可能準確地捕捉到純凈的語音訊號,同時將背景雜訊、雜音和其他外部影響降至最低。換句話說,麥克風和訊號處理有助於顯著提高自然語言處理品質。
要實作出色的語音辨識,必須用盡可能多的不同真人聲音對人工智慧進行訓練。只有這樣,它才能處理語音的微妙之處並理解口語文字。
適用於人工智慧音訊的MEMS麥克風
同自然語言處理的情況一樣,人工智慧音訊必須借助的硬體才能高品質地完成任務。首先是將人類語音產生的聲波轉換成電訊號,轉換品質直接關系到對所捕捉訊號的理解。任何轉換損失或劣化都會降低語音轉文字的準確率。
麥克風是音訊鏈中的第一個環節,在人工智慧音訊裝置必須選擇合適的麥克風。MEMS麥克風可謂當仁不讓:它們不僅具備高效能和低功耗,而且外形小巧,可輕松整合到各式各樣的裝置中。
MEMS麥克風主要由三個部份組成(圖2)。首先是用作傳感元件的微機電系統:膜片和背極板共同構成一個電容器,聲波使膜片振動,振動導致電容變化從而產生電訊號。第二個組成部份是專用積體電路(ASIC),其中包含向膜片施加電壓的電荷泵、放大器、穩定輸入電壓的穩壓器(LDO)和校準邏輯電路。第三個組成部份是封裝,它將這些元件集於一體,提供保護和遮蔽並形成後腔室。
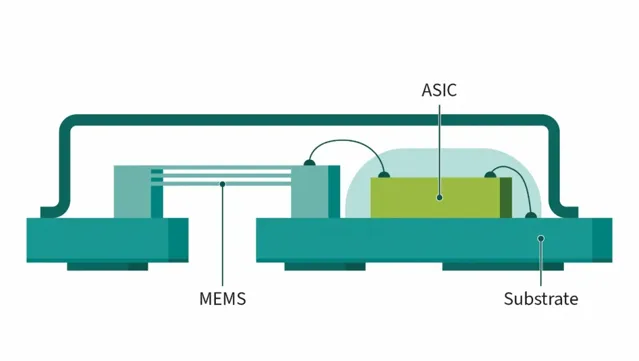
圖 2:MEMS麥克風框圖
要在有背景雜訊、口音或講話人與麥克風之間的距離不理想等困難條件下,辨識出語音的細微差別,麥克風的訊雜比是關鍵特性。麥克風的所有元件(MEMS、ASIC、封裝和入聲孔)都會產生自雜訊。訊雜比描述了麥克風固有的自雜訊相對於標準參考訊號的強度。訊雜比越高,能提供更穩定、更清晰的語音和數據傳輸,減少雜訊幹擾,提高裝置效能和穩定性。
XENSIV™ MEMS麥克風
帶給人工智慧音訊的優勢
如上所述,人工智慧音訊裝置需要采用高訊雜比麥克風來實作準確的語音辨識。英飛淩已經成功地研發了許多高效能MEMS麥克風²,包括具有革命性意義的密封雙膜(SDM)MEMS麥克風技術。它使用兩個膜片和一個帶電定子來形成一個密封的低壓腔(圖3)和一個差分輸出訊號,這種架構可實作超高訊雜比(高達75 dB)和極低失真,並為麥克風提供防水防塵高防護(IP57)。
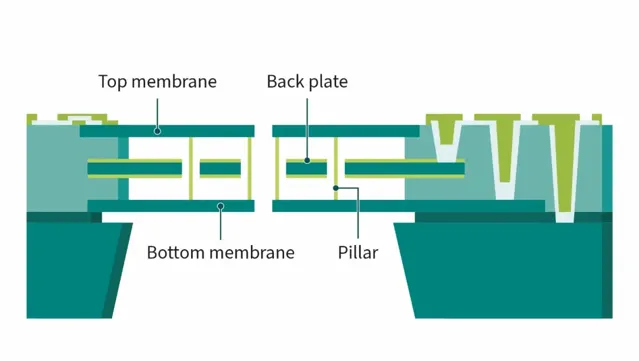
圖3:SDM技術使用兩個膜片和一個帶電定子
來形成一個密封的低壓腔和一個差分輸出訊號
從而實作超高訊雜比和極低失真
英飛淩XENSIV™ IM73A135正是套用了這個技術,訊雜比達到73 dB,處於行業內領先地位特別適合人工智慧音訊等要求嚴格的套用。其4×3 mm²封裝允許將聲音捕捉單元小型化,以便輕松將人工智慧語音技術整合到各種裝置中,包括膝上型電腦、會議電話以及智慧音箱和智慧型手機等。
XENSIV™ MEMS麥克風的另一個優點是低能耗。它們提供多種不同工作模式,透過節能來幫除了效能領先助提高裝置的功率效率。許多帶生成式人工智慧語音功能的裝置都是電池供電的人員攜行式裝置,低能耗對於延長電池續航尤為重要。
得益於其尺寸小巧、經濟劃算和低功耗,在一台裝置中配置多個麥克風。這樣可以檢測並降低背景雜訊,提高語音辨識準確率。還可以采用波束成形演算法,從背景雜訊中分離出並拾取特定講話人的語音。
如今人們很重視改善音訊品質,市場數據也反映出MEMS麥克風的優勢。高訊雜比MEMS麥克風市場的增長速度明顯超過低訊雜比麥克風市場。Omdia預計,訊雜比高於64 dB的MEMS麥克風在消費領域的復合年增長率將達到8.7%,到2027年銷售量將接近30億個³。
英飛淩很早就預見到這一趨勢,我們一直在研發適用於人工智慧音訊套用等的高效能MEMS麥克風。
除了效能領先的73-dB訊雜比之外,具備更高訊雜比、更低功耗的MEMS麥克風也即將相繼面市。
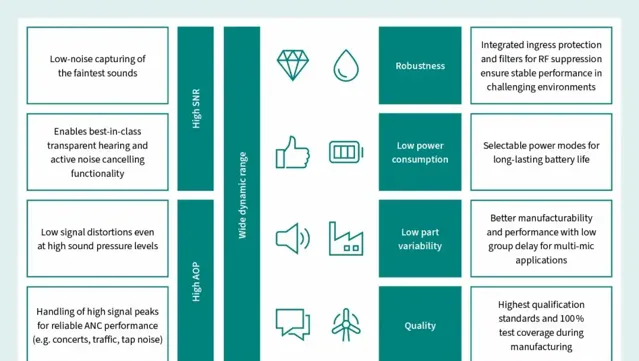
圖4:XENSIV™ MEMS麥克風的主要價值指標
如欲了解更多資訊,點選存取
結語
在生成式人工智慧音訊領域,高訊雜比MEMS麥克風起到了至關重要的作用。隨著人工智慧推動語音轉文字(STT)等音訊套用不斷發展,MEMS麥克風也透過捕捉細致入微的語音數據,為提高語音辨識準確率發揮了積極作用,助力在消費電子產品和面向視障群體的無障礙功能等領域實作更加自然而實用的人工智慧音訊。充分利用優質MEMS麥克風的這些優點,人工智慧音訊將在未來幾年開辟更多套用領域,包括語音複制、語音情緒辨識等等。
英飛淩科技自主研發和生產MEMS麥克風的所有元件。英飛淩可以針對每種套用,確定MEMS、ASIC和封裝的最佳組合以實作最優效能。這為改善使用者體驗和拓寬人工智慧音訊套用領域鋪平了道路。
參考文獻
1 SAR Insight & Consulting釋出的【語音助手平台預測】,2023年。
2 英飛淩科技。
3 Omdia(2023年釋出)【MEMS麥克風調研報告】。











