你對全快閃記憶體儲是什麽印象?
快!貴!容量低!都是土豪在用!
但是,買全快閃記憶體的,就都是「土豪」嗎?
不不不,其實註重價效比的懂行客戶,更鐘愛全閃!

為什麽呢?
我來先舉個大家都能懂的小例子↓
如果你有台舊電腦,效能不好,但只有500塊預算,怎麽利用有限的銀子獲得最大化效能提升呢?

答案很簡單, 把系統槽從HDD換成SSD。
你會發現,小小一個改變,效能竟然快到飛起
同樣的,換到企業級場景也一樣的。比如你把伺服器換成NVMe盤,給NAS加個SSD緩存,把機械盤陣換混閃,把混閃改全閃…
當然企業級儲存,並不是簡單地HDD換SSD那麽簡單,要充分發揮快閃記憶體優勢,軟體架構上也要下足功夫。即便如此,帶來的提升,也是立竿見影。
所以,用「全快閃記憶體」,竟然是超有價效比的IT基礎架構升級方案。
尤其這兩年數據爆炸,AI等新興場景越來越多,傳統「熱溫冷」數據分層儲存的理念已經out了。
以前,大家只用全快閃記憶體儲最熱的線上交易型數據,把有限的預算花到刀刃上。
現在越來越多溫數據,變成熱數據,冷數據也要快速熱起來,否則跟不上節奏,耽誤了大事。

客戶早就厭倦了把數據從不同儲存介質之間搬來搬去,他們開始盤算自己的家底:
有沒有可能把機械硬碟徹底幹掉?有沒有可能把全部儲存都換成全閃?選哪個乙方廠家來扛活?
一旦這種想法萌芽出來,就一發不可收拾,簡直夜不能寐啊。
那麽,現有的技術架構,能不能滿足客戶把「全部數據」都存到「全閃」裏面呢?
乍一看,還是頗有些難度的。
雖然SSD這些年的價格一直在降,但是,與機械硬碟的相比,還是有不小的差距。
即便依靠快閃記憶體的降價、緩存的堆疊,可以把每IOPS的成本降下來,但是每TB的絕對成本,仍然讓客戶不得不反復權衡。
想把全部數據「All in 快閃記憶體」的目標,看起來還是那麽遙遠。
那麽,到底有沒有那種 兼顧效能 與 成本優勢 的分布式全閃?滿足客戶日益迫切的「全全閃」訴求?
最近,我看到一家專業儲存廠商,搞出了一套全新的架構,把分布式全閃的體驗拉升了一大波。
這家公司,就是「XSKY星辰天合」,國內獨立儲存廠商中的「最能打」的那一個。
根據IDC的統計數據,自2020年以來,XSKY在中國SDS市場中,始終位列領跑者行列(獨立SDS廠商第一,物件儲存軟體市場第一)。
XSKY經過8年在儲存技術領域不斷打磨實踐,以最新的標準儲存協定和網路技術作為基礎,推出了「星海架構」。
他們的目標,就是希望透過架構創新,推動全閃普惠,讓「全全閃」成為可能。
總體來說,星海架構包括了三大創新點↓
1、Shared-Everything全共享架構,擴充套件性、靈活性、故障恢復能力大幅提高
在各種分布式儲存、資料庫系統中,過去非常流行的是「Shared Nothing架構」。
Shared-Nothing的初衷是規避節點間網路頻寬不足,每個節點物理資源隔離,獨立處理數據,各人自掃門前雪,盡量減少跨網、跨節點處理數據,從而降低延遲。
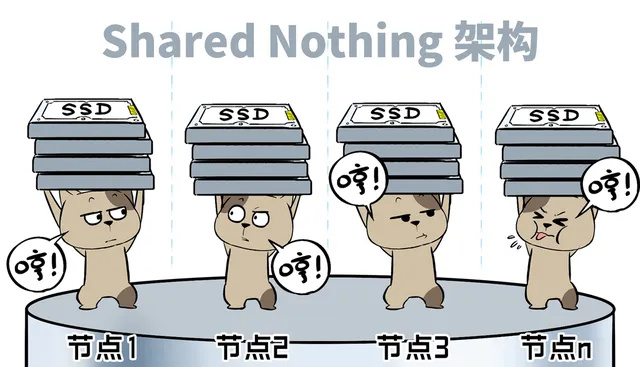
但是,資源的獨立性限制了靈活性,所有節點無法統一利用,形成資源不均浪費,無法進行 高效的大比例全域糾刪 冗余,數據恢復、後台IO也難以全域最佳化。
同時,隨著節點增多,為了維持分布式事務的一致性,會帶來額外的軟體復雜性和CPU開銷,並導致更嚴重的「寫放大」問題。
隨著NVMe標準成熟和網路頻寬提升,跨節點的存取延遲已經不再是主要矛盾,因此, XSKY拋棄了這種業界沿用多年的 Shared-Nothing 架構,大膽采用了 Shared-Everything 架構。
具體來看,每個儲存節點上的ChunkServer、FileServer、BlockServer,都以無狀態容器化方式執行,大家基於共享記憶體互通,沒有額外網路開銷。
而每個儲存節點的IO Server將本節點的SSD透過NVMe-oF協定暴露出物理卷,這樣任何ChunkServer都可以掛載集群裏的所有NVMe卷。
這種架構讓分布式儲存突破節點局限,任意SSD都可以被全域存取,容量/效能與單個節點的CPU/記憶體解耦。
也可以更好地進行全域流控,後台任務排程,並根據全域 SSD 的狀態進行磨損均衡。
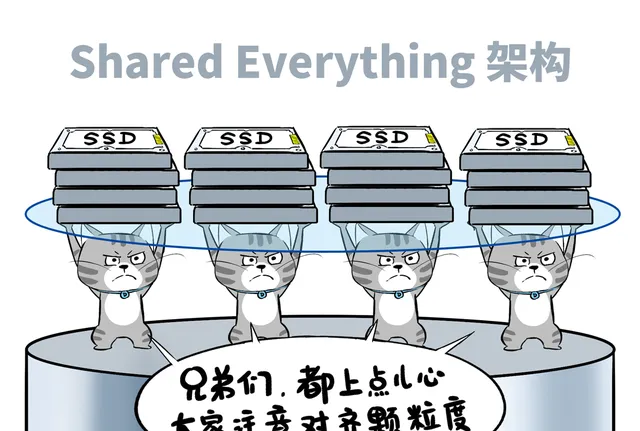
全域SSD可見,也讓實施更大比例的EC糾刪碼成為可能,有效提升得盤率(配合壓縮技術,得盤率超過100%)。
橫向擴充套件時,節點間不需要通訊,消除了東西流量,可實作線性擴充套件。
以前,采用Shared-Nothing架構,節點間需要復雜的一致性協商,故障時,恢復時間長達數秒,這種服務級別很難應對當下的關鍵業務場景。
現在,無論慢盤還是網路亞健康問題,無須等待數據復制或者狀態同步,100毫秒內即可快速切換。
至此,星海架構透過Shared-Everything,打通了分布式全閃的「底層邏輯」,擴充套件性、可靠性、靈活性、得盤率都得到了顯著提升。
2、單層快閃記憶體介質,專門面向TLC NVMe SSD最佳化,成本大幅降低
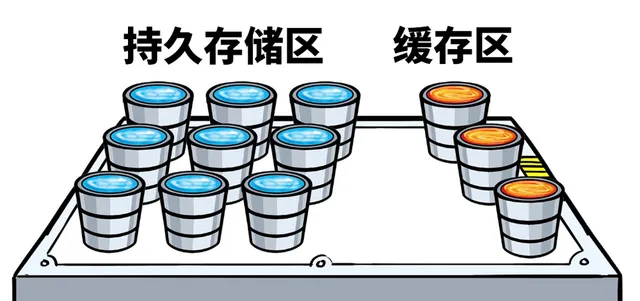
星海架構采用了單層TLC NVMe SSD來構建儲存池,簡化集群的硬體結構。
TLC SSD具備更高的儲存密度和更優的成本。但是傳統全閃通常采用分層架構,緩存層需要配備DWPD更高的快閃記憶體,造成集群結構復雜且成本高昂。
星海架構專門針對TLC SSD的特點進行最佳化,采用單一儲存層架構,不再設定單獨的緩存層,顯著降低介質成本20%以上。
針對快閃記憶體的「寫放大」問題,星海架構采用了Append Only方式來更新數據,最大化減少「寫放大」,提升SSD壽命,進一步降低成本。
↓
同時,透過精心設計的空間布局,在單個 SSD 上實作緩存和持久儲存的雙重功能。
保障在沒有專用的緩存介質情況下,仍然可以提供足夠的效能穩定性。
3、采用端到端NVMe協定,最大化硬體解除安裝
星海架構不僅在儲存存取方面采用了NVMe over Fabrics協定,在儲存企業網路絡中,也全面實施了NVMe-oF。
這意味著所有儲存節點都透過NVMe over Fabrics高效存取每個NVMe SSD,避免了儲存協定轉換所帶來的額外開銷。
效能決定了儲存的上限,可靠性決定了儲存的下限。
在不斷叠代的NVMe SSD和高速網路加持下,絕對效能跑出個好看的分數不是問題。這方面,XSKY的星海架構已經非常「能打」。
但XSKY並不滿足於絕對效能摸高,作為儲存老兵,他們深知規模化全閃裏面,在支持大規模寫入和後設資料更新的情況下,長期的尾部延遲才是衡量儲存效能服務水平的關鍵。
一錘子買賣並非真高手,持續穩定輸出才是真功夫。
星海架構在三大創新技術的加持之下,整體效能服務水平獲得了巨大提升↓
在40%負載情況下,端到端延遲低至 100微秒 ;面對慢盤、亞健康網路時, 100毫秒 內快速切換;透過大比例EC和資料壓縮技術,實作超過 100% 的得盤率。
在這樣的整體效能服務水平下,成本也獲得了極大的最佳化,讓客戶不再對全閃的價格望而卻步。
全閃普惠時代到來,「All Data on All Flash」終於成為可能。
基於星海架構,XSKY的新一代分布式全閃產品星飛9000也隨之橫空出世。
作為業界首款采用全共享架構的分布式主記憶體儲,星飛9000一體機包含星飛軟體和專屬硬體,提供全場景儲存業務支撐能力,並有信創機型備選*。
從資料庫關鍵業務場景,到互聯網高並行場景,再到實分時析場景,星飛用一套儲存架構,承載客戶全量數據,而無需在不同的介質之間,導來導去。
XSKY的野心是用一套星飛來替代NVMe本地盤、全閃陣列和容量型儲存,既然想要「一打三」,就要看看實戰的時候,到底行不行。
在實測中,星飛9000果然不負眾望,表現相當炸裂。
看罷星飛的實戰結果,我們有理由相信,透過架構創新,的確給全閃帶來了質變。
低成本、高效能服務水平的分布式全閃,正撲面而來。全「全閃」時代,離我們只有一步之遙。
大家開始換「全全閃」了,你還不抓緊?











